小米监控系统Falcon的历史数据,被存储在Rrd文件中,每个Rrd文件均无副本,存在单点问题。为了保障历史数据的高可用,我们进行了一些实践,整理成下文。
数据高可用,本质上是维护多个数据副本。数据副本的维护,通常有两种方式: 热备份和冷备。在Falcon历史数据的高可用实践中,我们分别对这两种方式进行了尝试。
热备份
热备份,需要实时维护2+份完全一致的数据副本。”实时&完全一致”的要求太苛刻,我们根据Falcon的业务特点做了退化:允许不大于一个周期的同步延迟,允许微量(<0.1%)的数据丢失。
Falcon历史数据,是经过transfer转发、由graph实例保存在本机的Rrd文件中的。一个很自然的想法是,部署两套实例数相同的graph集群,transfer按照相同的哈希规则、将同一份数据双打至这两个graph集群,这样就能得到两分完全一样的监控历史数据、每个Rrd文件都能在远端找到一个对应的副本。
热备份需要生产环境的transfer和graph组件协同工作。进行热备份时,额外部署一套graph集群,并修改transfer的配置。这里举个例子。假设你的Falcon系统,未做热备份时,部署情况为:
# graph集群
"cluster": {
"graph-01":"falcon.graph01.bj:6070",
"graph-02":"falcon.graph02.bj:6070"
}
# transfer的graph.cluster配置
"cluster": {
"graph-01":"falcon.graph01.bj:6070",
"graph-02":"falcon.graph02.bj:6070"
}
进行热备份时,部署如下。用于热备份的graph集群,其实例名称,要和原集群的完全一致,这样transfer才能使用相同的哈希规则进行”双打”。
# graph集群
"cluster": {
"graph-01":"falcon.graph01.bj:6070",
"graph-02":"falcon.graph02.bj:6070"
}
# graph的备份集群
"cluster": {
"graph-01":"falcon.graph11.bj:6070", // 实例名graph-01要和原集群保持一致
"graph-02":"falcon.graph12.bj:6070"
}
# transfer的graph.cluster配置
"cluster": {
"graph-01":"falcon.graph01.bj:6070,falcon.graph11.bj:6070", // 这样配置后, 同一份数据会被同时发送给 实例falcon.graph01.bj:6070 和 实例falcon.graph11.bj:6070
"graph-02":"falcon.graph02.bj:6070,falcon.graph12.bj:6070"
}
进行完上述配置后,依靠transfer的数据双打 和 graph的数据归档功能,就能实现历史数据的热备份。以节点”graph-01”为例,transfer会向graph实例falcon.graph01.bj和falcon.graph11.bj发送相同的监控数据,graph服务按照相同的存储和老化规则、将这些数据存储在同名的Rrd文件中,这样两个实例上就有了完全相同的历史数据、可以互为热备份。如果实例falcon.graph01.bj出现故障,可以直接踢掉之、用其备份实例falcon.graph11.bj做替换,迅速恢复服务,然后,再慢慢的处理实例falcon.graph01.bj的故障;如果实例falcon.graph01.bj上的某个Rrd文件被破坏,可以从实例falcon.graph11.bj上拷贝同名Rrd,很快的修复被破坏的文件。
使用热备份,优点是:故障恢复迅速、故障恢复操作简单、历史数据基本无丢失。缺点是资源消耗大增:(1)graph组件的资源消耗增加100% (2)transfer组件的数据转发压力增加50%。出于成本考虑,我们没有使用热备份的方案。如果Falcon集群规模不大或者公司有财力支持,你可以考虑使用热备份方案。
冷备份
冷备份,是定时的、将历史数据备份到远端服务器上。
数据冷备份,是一个独立的任务,不需要生产环境的Falcon组件参与。比较依赖人肉运维,需要做好数据备份的规范。不同graph实例的冷备数据,应该独立存放,以方便故障恢复。
环境准备
这里,仍然用一个例子来说明。假设graph实例有2个实例,历史数据的存储目录如下:
# graph集群,及历史数据存储目录
"cluster": {
"graph-01":"falcon.graph01.bj:6070",
"graph-02":"falcon.graph02.bj:6070"
},
"rrd": {
"storage": "/home/work/data/6070"
}
历史数据冷备主机有1台,冷备数据存放目录如下。为了便于建立备份数据与原始数据的联系,我们用生产环境的graph实例地址、作为其备份数据的存储目录。
# 历史数据冷备主机
falcon.graph.backup01.bj:
/home/work/data/falcon.graph01.bj/6070 // rsync from falcon.graph01.bj:/home/work/data/6070
/home/work/data/falcon.graph02.bj/6070 // rsync from falcon.graph02.bj:/home/work/data/6070
/home/work/open-falcon/graph.backup // 存放 数据冷备相关的脚本
冷备主机可以有多台,越多越难维护。因此,建议冷备主机配备足够大的磁盘容量、合理减少冷备主机的数量。
冷备过程
冷备时,我们将历史数据拷贝到冷备主机上,做法是:每日凌晨00:00,使用rsync工具,将各graph实例上的Rrd文件,同步到远端的冷备主机上。我们会在冷备主机上,对各graph实例,发起rsync请求,进行历史数据的远程拷贝(再完善一点的话,完成数据拷贝之后,需要check冷备数据的可用性)。为此,需要做如下工作:
- 安装rsync工具。在graph实例所在主机和冷备主机上,安装rsync工作,冷备主机为rsync的客户端
- 设置ssh信任关系。我们选择使用rsync的ssh通道,需要提前做好免密码的登录认证,这样执行rsync时就不需要输入密码了
- 建立数据备份目录。在冷备主机上,建立相应的数据备份目录。这里需要一个好的规范
- 准备rsync脚本。准备好发起rsync所需要的所有脚本,我们会在后文给出这些脚本
- 添加crontab。在冷备主机上,添加一条crontab,用于周期性的发起数据备份
冷备主机上的crontab任务,定义如下。我们把rsync备份脚本放在了目录/home/work/open-falcon/graph.backup下。
0 0 * * * cd /home/work/open-falcon/graph.backup && bash backup.sh &>/tmp/graph.backup.log
备份脚本如下,包括backup.sh、rsync.sh 和 graph.list。backup.sh是顶层文件,它从graph.list读取到graph实例信息,然后针对每个graph实例的历史数据,分别调用rsync.sh脚本、发起远程数据备份;一个graph实例的历史数据备份执行完后,rsync.sh脚本会向监控系统发送一组统计数据、说明这个数据备份成功与否、耗时多少等信息,统计信息的endpoint是graph实例所在的机器名,这样,可以方便用户从screen中观察数据备份的状态。
backup.sh的脚本内容,如下
cur_dir=$(cd $(dirname $0)/; pwd)
data_dir=/home/work/data
cd $cur_dir
tmp=$cur_dir/tmp
list=$cur_dir/graph.list
rsyncsh=$cur_dir/rsync.sh
mkdir -p $tmp
# check
if [ ! -f $list ]; then
echo -e "[error] miss graph list file"
exit 1
fi
# rsync async
ts=`date +%s`
echo -e "[start], $ts"
for host in `cat $list`;
do
nohup bash $rsyncsh "$host" "$tmp" &>/dev/null &
echo -e "rsync $host"
done
echo -e "[done] async, `date +%s`"
rsync.sh的脚本内容,如下
host=$1
log_dir=$2
if [ "X$host" == "X" -o "X$log_dir" == "X" ];then
echo -e "bad arg"
exit 1
fi
# rsync
start=`date +%s`
rsync -avz --bwlimit=10000 work@$host:/home/work/data/6070 /home/work/data/$host/ &>$log_dir/rsyncsh.$host.$start.log
ecode=$?
end=`date +%s`
# time.consuming
tc=`expr $end - $start`
# statistics
curl -X POST -d "[{\"metric\":\"graph.backup.status\", \"endpoint\":\"$host\", \"timestamp\":$start, \"step\":86400, \"value\":$ecode, \"counterType\":\"GAUGE\", \"tags\": \"pdl=falcon,service=graph,job=backup\"}, {\"metric\":\"graph.backup.time\", \"endpoint\":\"$host\", \"timestamp\":$start, \"step\":86400, \"value\":$tc, \"counterType\":\"GAUGE\", \"tags\": \"pdl=falcon,service=graph,job=backup\"}]" http://127.0.0.1:1988/v1/push
graph.list的配置信息,如下
falcon.graph01.bj
falcon.graph02.bj
为了人工验证冷备数据的完整性,我们搭建了一个check链路: 冷备数据 -> graph -> query -> dashboard。在冷备主机上,针对每一个graph实例的冷备数据,部署一个新的graph服务,这个新服务只是用于读取这份冷备数据。query和dashboard,可以部署在冷备主机或者其他任何机器上。query的graph列表,地址要配置成冷备机上新搭建的graph实例地址,名称要配置成 生产环境的graph实例名称,一个例子如下。
# check链路的query配置。请确保query的版本不低于1.4.0;低版本的query,需要在graph_backends.txt中配置graph列表
"graph": {
"connTimeout": 1000,
"callTimeout": 5000,
"maxConns": 32,
"maxIdle": 32,
"replicas": 500,
"cluster": {
"graph-01": "falcon.graph.backup01.bj:6071", // 指向冷备主机上的graph实例falcon.graph.backup01.bj:6071,对应于实例"falcon.graph01.bj:6070" 的冷备数据。下同
"graph-02": "falcon.graph.backup01.bj:6072"
}
优缺点
使用冷备方案,会节省很多硬件资源。同时,也有很多坏处:
- 数据丢失。最多,可能丢失一个备份周期(默认24h)的数据
- 故障恢复缓慢。故障恢复时需要做数据拷贝,拷贝海量的Rrd小文件是一项很耗时的工作,如拷贝200W个文件,通常需要1+h(这里有优化空间,我们没有去做)
- 实现复杂。需要维护独立的数据冷备服务
- 太多人肉。数据冷备、故障恢复时,都需要很多的人工参与
最终,由于监控系统资源使用方面的压力及部分其他原因,我们选择了数据冷备的方案。
统计数据
这里,提供一组我们线上数据冷备的统计信息,供大家参考。
我们的graph主机和冷备主机,基本信息如下。冷备过程,主要消耗磁盘IO资源,占用的网络带宽资源有限,CPU、MEM的消耗也较少,因此在这里我们只列出了磁盘的情况。
| 主机类型 | 机器数量 | 机器名称 | 磁盘配置 | 磁盘空间使用率 |
|---|---|---|---|---|
| graph主机 | 20 | graph21.bj...graph40.bj | S3500 SSD, 3.6T | 无需关注 |
| 冷备主机 | 4 | graph-backup01.bj...graph-backup04.bj | 7200转 SAS, 6.4T | 40% |
每台冷备主机,负责存储5个graph实例的历史数据,大概2.5T数据、800W个监控指标项。graph实例的主机配置了高性能的SSD磁盘,能够轻松hold住rsync期间的io压力,因此我们没有太多关注之。冷备主机要在短时间内同步大量数据,但使用了普通的机械磁盘,disk.io压力较大。如下所示,rsync期间,4台冷备主机的disk.io被打满,disk读写均达到了上限。
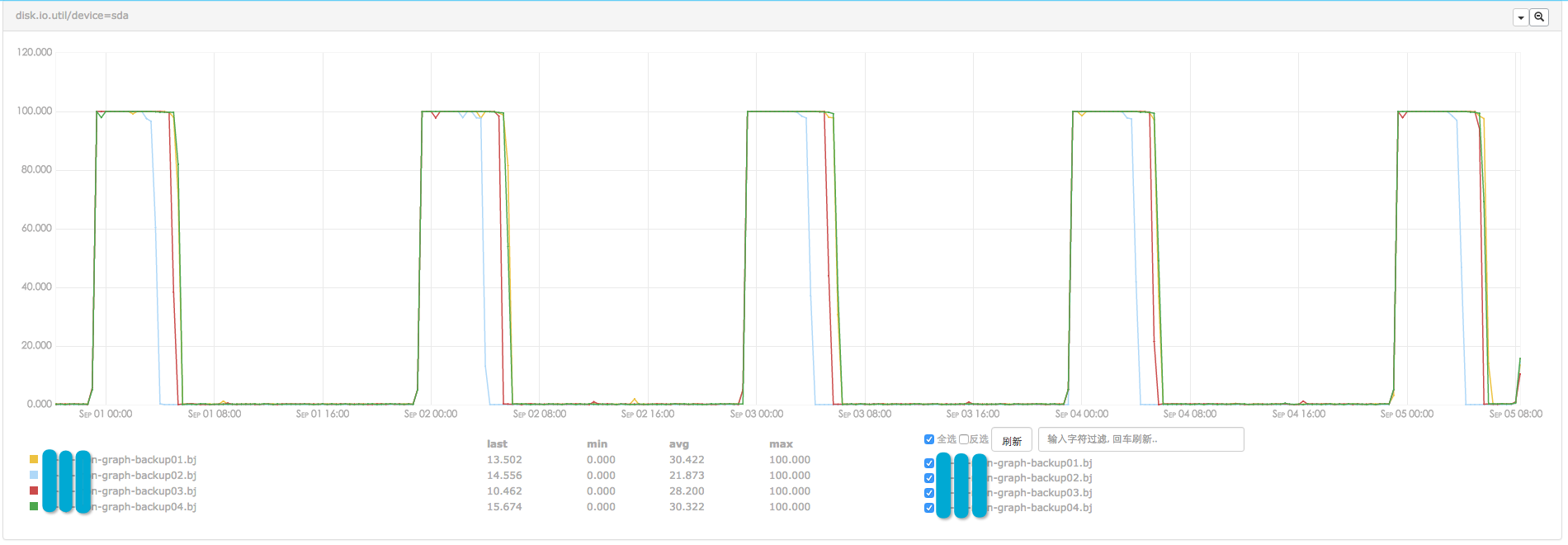
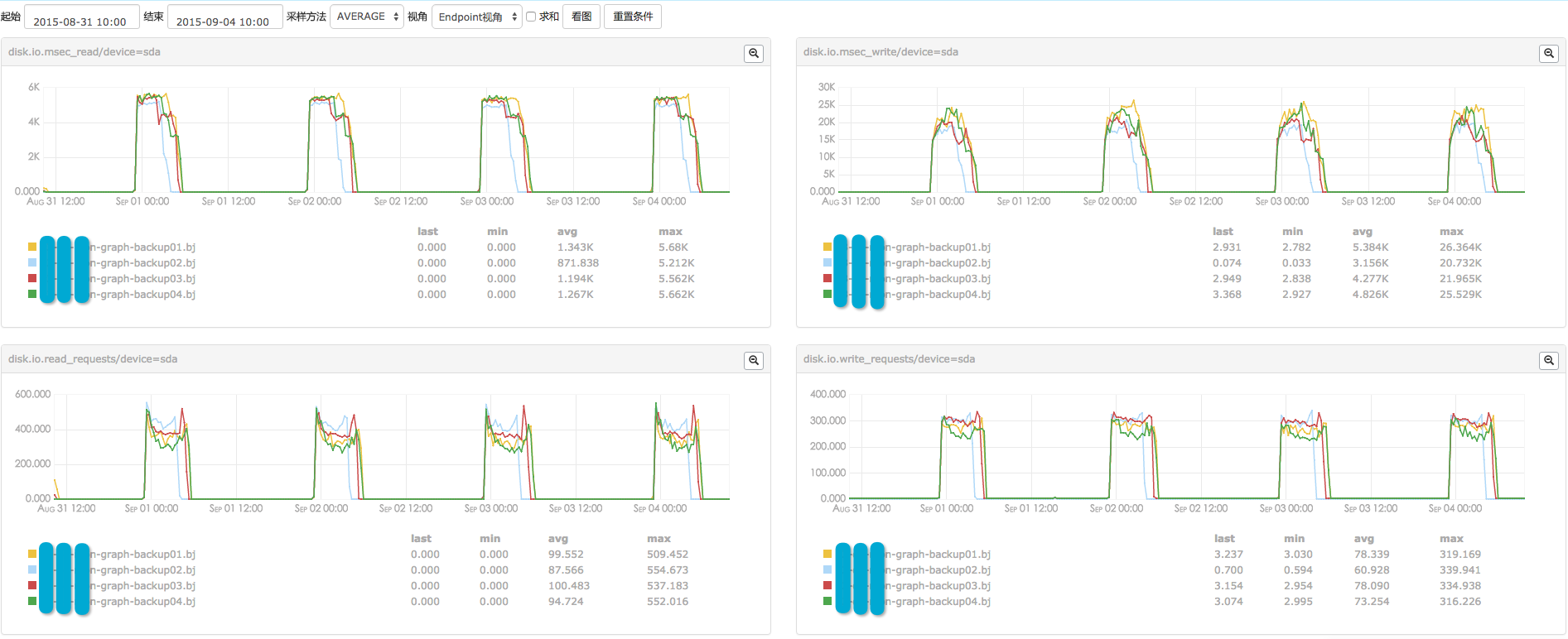
一次rsync过程,耗时较长。根据graph实例上监控指标数量的不同,同步一个实例的历史数据,少则耗时4h,多则耗时8h,分布如下。rsync发生在凌晨期间,虽然耗时略长,但基本不会影响用户正常使用监控系统。
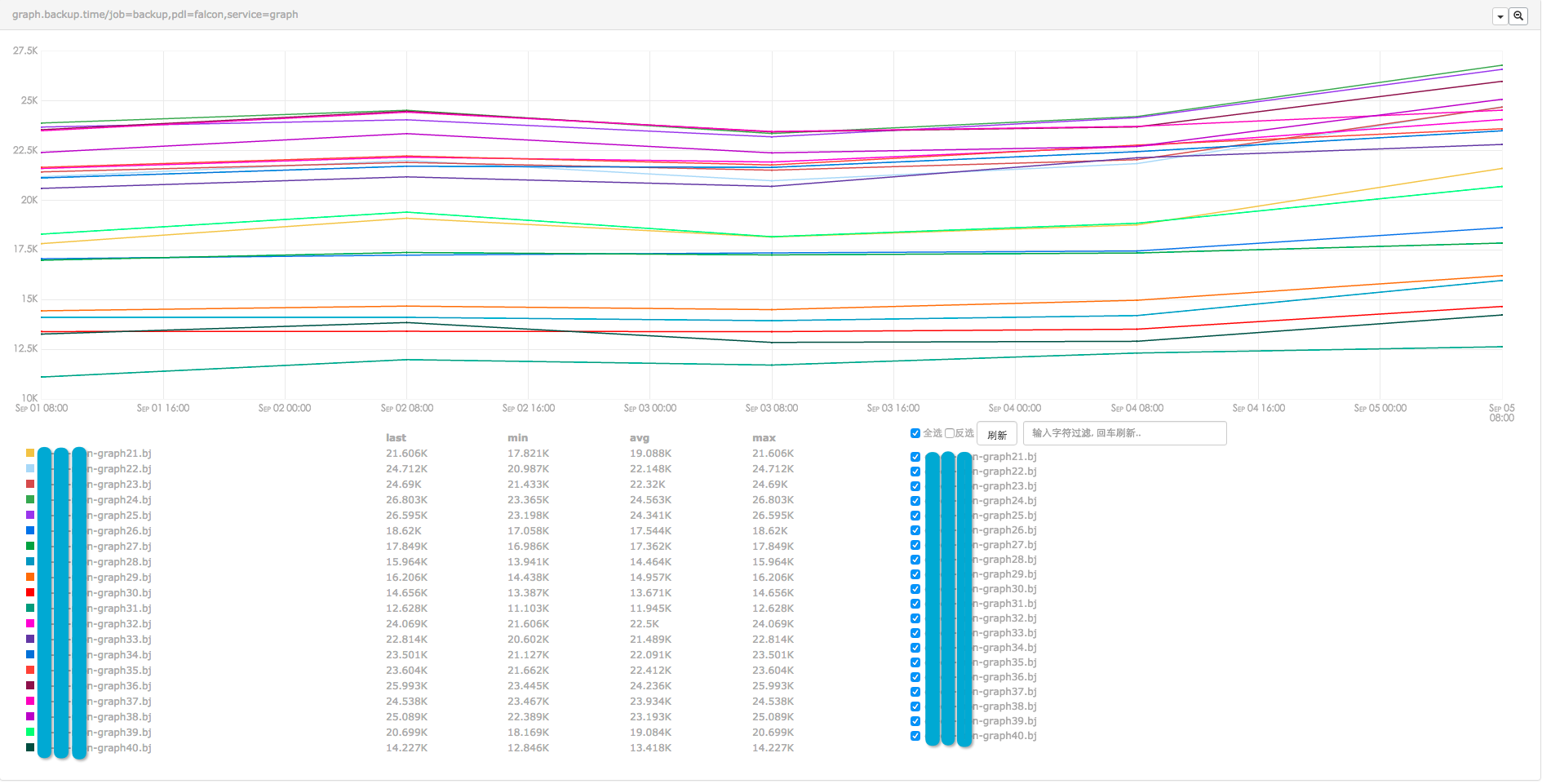 值得注意的是,随着冷备主机磁盘空间使用率的增加,rsync会逐渐变慢。
值得注意的是,随着冷备主机磁盘空间使用率的增加,rsync会逐渐变慢。
总结
Falcon历史数据高可用方案的选择,与用户具体需求、资金投入程度等有很大关系,应该视实际情况而定。后续,我们有计划将历史数据存入HBase,减少高可用、扩容等方面的投入。