加入小米监控团队有半年时间了,能与领域里的牛人们共事,很开心。当然,时不时会想起am团队的童鞋。闲话不多说了,今天介绍下小米的监控产品Falcon。
Falcon是一套企业级的监控解决方案,偏向于平台化,主要提供 实时报警、监控数据展示等功能。本文试图从系统架构、数据模型、数据采集、数据收集、数据存储、数据查询、图表展示、报警配置等方面,介绍Falcon的实现。
系统架构
模块组成
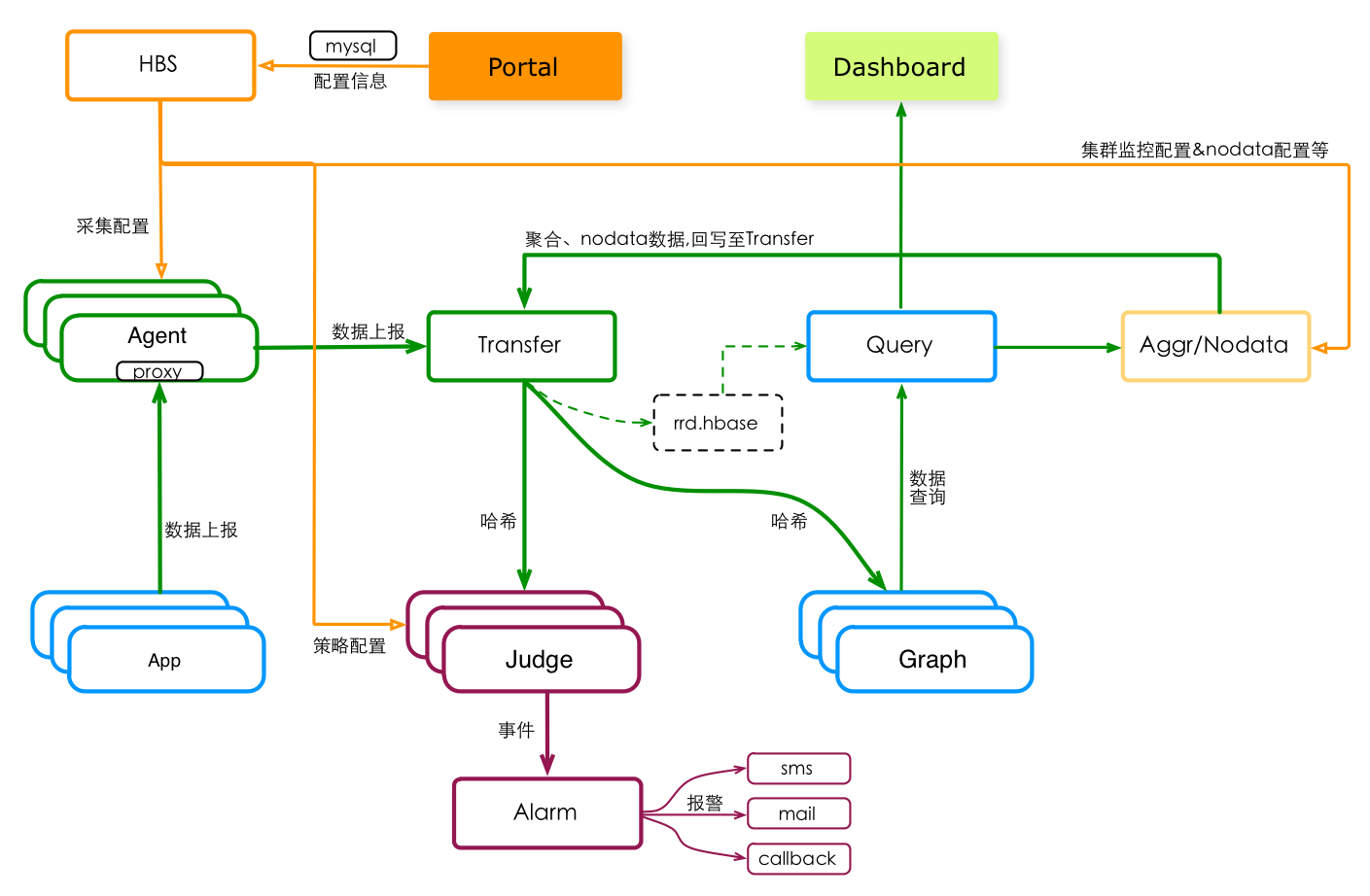
转发服务Transfer,负责收集监控数据,并将收集到的监控数据哈希分片、发送给Judge&Graph(以及正在测试中的 持久化存储rrd.hbase)。Agent采集的数据、用户push的数据,最终都会通过Transfer,进入监控系统。
Graph组件收到监控数据后,将这些数据悉数存储在本地的Rrd数据库,并借助Rrd的归档功能将这些监控数据进行抽样存储。Query组件提供查询绘图数据的Api入口,从Graph组件上读取数据、返回给高层的监控数据消费者。Dashboard是展示监控数据曲线的WEB应用,从Query拿数据、展示在UI上。
Judge组件负责报警判断,它从Transfer处获取监控数据、从HBS处获取报警策略的配置,进行实时的报警判断,生成报警事件。Alarm组件消费Judge产生的报警事件,并产生有效的报警动作。当前,Falcon支持短信、邮件、Http回调等报警动作。
Portal是Falcon的门户,为用户提供了配置报警策略、集群监控、Nodata的UI,并将这些配置信息存储至mysql。HBS是Falcon的配置中心,消费mysql的配置信息、并转化为后端服务乐于接受的形式。
集群监控Aggr和Nodata监控,是Falcon近期新增的服务组件。他们都从HBS拿配置信息、从Query拉取监控数据。Aggr将多个单机的监控信息,聚合成集群维度,然后吐回监控系统。Nodata则实时监督监控数据的上报,发现中断的情况就产生用户自定义的超时数据、并吐回到监控系统。
部署方式
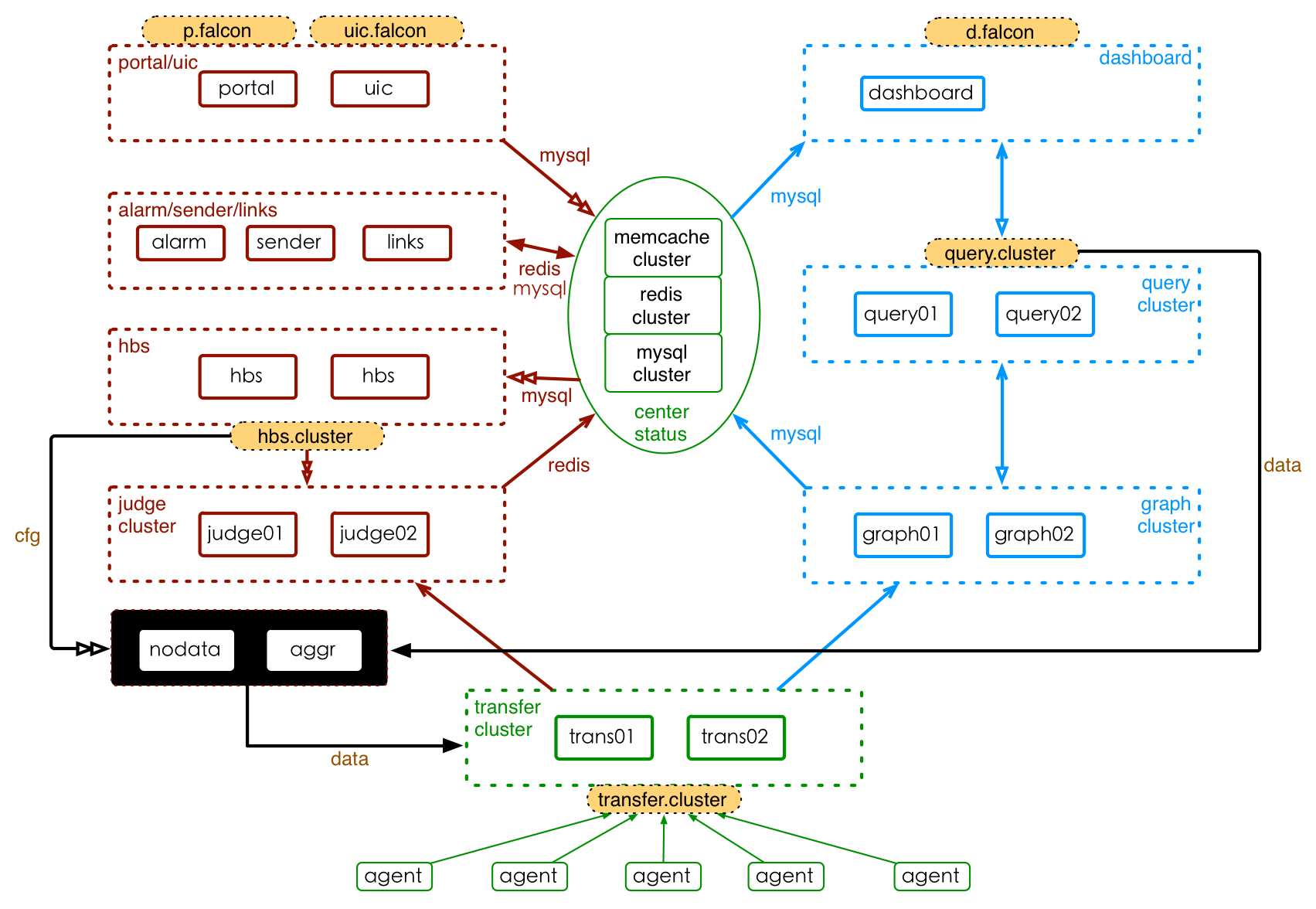
Falcon是一个比较大的分布式系统,有十几个组件。按照功能,这十几个组件可以划分为 基础组件、作图链路组件和报警链路组件,安装部署的架构如下图所示。其中,基础组件以绿色标注圈住、作图链路组件以蓝色圈住、报警链路组件以红色圈住,橙色填充的组件为域名。Transfer、Query、Judge、Nodata、Aggr、Dashboard、Portal等都是无状态集群,可以自由的水平扩展;Graph集群部署,但存储了监控数据信息,水平扩展时需要做历史数据的迁移。
Falcon组件的部署形态,会随着监控数据量的不同而发生变化。当系统接收5000+万个采集指标的数据、QPS接近 50W条数据/s 时,可以进行如下规划: Transfer部署20个实例,Graph部署20个实例,Judge部署20个实例,Query、Dashborad、Portal各部署2-5个实例,Hbs、Uic、Alarm、Sender、Links部署1-2个实例。
如果需要了解小米部署Falcon的实践经验,可以参考《Falcon部署实践》一文。
数据采集
数据是监控系统所有信息的源头,不论是报警还是绘图展示。那么,监控系统是否有必要亲力亲为地负责所有监控数据的采集?
监控系统的两个核心工作,是实时报警和数据展示,把这两个核心工作搞定了,监控系统就能健康的run起来。这两个核心功能,可以做的很通用、很纯粹,进而很容易维护。
反观数据采集,经常会涉及到千差万别的业务细节。比如,网络设备的状态数据采集,会因为生产厂商、设备型号、设备类型的差异,导致数据采集的方式差别很大。再比如,线上各业务线的数据采集,其获取方式更是千差万别、不一而足。监控开发团队要覆盖所有的数据采集工作,就要涉及到各业务的细节,必然会被业务所累,一不小心,监控开发团队的主要精力就花在了各业务线上。
当然,有很多数据采集需求是通用的、或者较通用的,如果监控系统能够帮忙做数据采集,会大大提高全局的工作效率。对于种情况,监控开发团队应该提供支持。
结论是什么呢?监控系统应该负责搞定通用数据的采集,非通用数据的采集由用户自己完成。Falcon提供了Agent及插件机制,用于采集通用的数据;同时,制定了良好的数据准入规范,准备了丰富的数据接收器,使的用户能够完成监控数据采集、并很方便的push到监控系统。
数据采集演进
监控系统的数据收集可以做成这样:不关注数据是怎么采集的,只需要制定数据格式标准、让用户按照标准把数据push上来即可。可以认为,监控系统可以不关注数据采集、只做数据收集。
1.Agent基础采集
但有一些监控指标,在运维工作中经常被用到。这类指标大多与机器相关,主要包括Cpu、Load、Mem、Disk、IO、Net、Core、Port、Process、NTP、DNS等。为了方便用户使用,监控系统要帮忙采集这些数据: 做一个本机数据采集的代理Agent、安装到机器上,然后由Agent主动采集本机信息、自动push给监控系统;用户不需要做任何工作,就能把这些数据送入监控系统。
2.Agent插件机制
Agent支持的基础采集项,基本能覆盖到常见的监控需求。但仍然会存在一些特殊的业务需求,或者不适合内置于Agent的采集项,为了cover这些需求,插件机制应运而生。插件是符合一定规范的,由用户开发的数据采集脚本或者可执行程序,Agent会负责周期性的调度这些插件,并将插件运行的标准输出,推送到监控系统。用户可以配置,哪些机器需要执行哪些插件。插件机制,是对Agent数据采集能力的扩展,更加灵活多样;同时,插件涉及的链路较长、复杂度较高, 往往会成为很多bug的丰富来源。
3.自维护采集服务
不能或者不方便 通过Agent及其插件机制 采集的监控指标,需要用户自己完成数据采集、自己将数据push到监控系统。为此,监控系统需要制定灵活的数据模型,来支持用户自定义数据的采集;同时,还要提供简单易用的数据接收器,方便用户push数据。
在庞大的用户自维护采集服务中,有一些是较通用的,比如网络设备监控、Java应用监控、Nginx监控、Mysql监控、HBase监控、Redis监控等。上述采集工作,需要由具体的业务部门负责;监控团队可以协助、但不应该接手。
4.Nodata监控
对于用户自维护的采集服务,监控其存活状态是一个通用需求。为此,监控系统提供了Nodata功能,以此,监督数据采集服务(包括Agent)的可用性。
至此,监控系统的数据采集工作,基本覆盖完全。
数据模型
数据模型,是监控系统的数据准入规范,约定了监控数据的格式。数据模型,应该满足一些约束:
-
数据模型,要包含完整的信息。Falcon不要求用户预定义采集指标,因此一条监控数据需要包含完整的”身份信息”,通过这条数据的内容就能确定其所有元信息。
-
数据模型,要足够灵活。比如以zabbix为例,上报的数据为hostname、metric,那么用户添加告警策略、管理告警策略的时候,就只能以这两个维度进行。举一个最常见的场景:hostA的磁盘空间,小于5%,就告警。一般的服务器上,都会有两个主要的分区,根分区和home分区,在zabbix里面,就得加两条规则;如果是hadoop的机器,一般还会有十几块的数据盘,还得再加10多条规则,这样就会痛苦。
借鉴OpenTSDB的数据结构,结合上述约束,Falcon采用了如下的数据模型,其中:
- metric: 最核心的字段,代表这个数据采集项具体度量的是什么东西,比如内存的使用量、某个接口的调用次数
- endpoint: 监控实体,代表metric的主体,比如metric是内存使用量,那么endpoint就表示该metric属于哪台机器
- tags: 这是一组逗号分隔的键值对,用来对metric进行进一步的描述,比如service=falcon,location=beijing
- timestamp: UNIX时间戳,表示产生该数据的时间
- value: 整型或者浮点型,代表该metric在指定时间点的取值
- step: 整型,表示该数据采集项的汇报周期,这对于后续的监控策略配置、图表展示很重要,必须明确指定
- counterType: 只能是COUNTER或者GAUGE二选一,前者表示该采集项为计数器类型,后者表示其为原值;对于计数器类型,告警判定以及图表展示前,会被先计算为速率
{
metric: df.bytes.free.percent,
endpoint: hostA,
tags: mount=/home,
value: 5,
timestamp: unix.timestamp,
counterType: GAUGE,
step: 60
},
{
metric: df.bytes.free.percent,
endpoint: hostA,
tags: mount=/root,
value: 15,
timestamp: unix.timestamp,
counterType: GAUGE,
step: 60
}
上面的例子中,metric为df.bytes.free.percent,表示这个指标的具体含义为机器的磁盘可用百分比;endpoint描述这个metric所在的主体是hostA;tags是对这个metric的一组补充描述,比如mount=/home这一组tag,表示这个metric描述的是home分区的磁盘可用百分比,同样mount=/root,表示这个metric描述的是root分区的磁盘可用百分比。
使用tags的好处,是可以简化告警策略的配置。比如上面提到的这个最简单的场景,hostA的磁盘可用百分比,小于5%就触发告警。对于root和home两个分区,在Open-Falcon中,可以用一条规则来描述、而不再需要针对两个分区写两条规则:
// 使用tags
endpoint=hostA && metric=df.bytes.free.percent < 5%
// 未使用tags
endpoint=hostA && metric=df.bytes.free.percent && mount=/home< 5%
endpoint=hostA && metric=df.bytes.free.percent && mount=/root< 5%
另外,在Dashboard中,可以借助于tags,把tags作为筛选过滤条件,更方便用户查看自己关心的指标。
数据收集
从用户角度,Falcon提供了两个数据收集器:Agent和Transfer。Agent最终会把收集到的数据上报给Transfer。
Agent收集器,提供本机数据收集的通道。Agent被安装在每一台服务器上、覆盖面很广,用户使用起来很方便。如,用户通过linux的crontab来采集监控数据,采集完成后直接push到本地的Agent上,很方便。向本地Agent上报数据,不会有ACL的问题。如果要上报的监控数据量很大,不宜使用本地Agent,因为Agent的数据路由能力有限、且容易消耗过多的本机资源。
Transfer收集器,提供了远端数据收集通道。对于数据量很大的采集服务,适合直接将数据push给Transfer。Transfer的单机数据接收能力很强,且集群部署,整体上可以hold住用户的大流量push。如,负责用户访问质量分析的Storm集群,产生海量的监控数据,这些数据是通过Transfer上报至监控系统的。Transfer一般部署在中心机房,向其push数据时会有ACL的问题,需要注意。
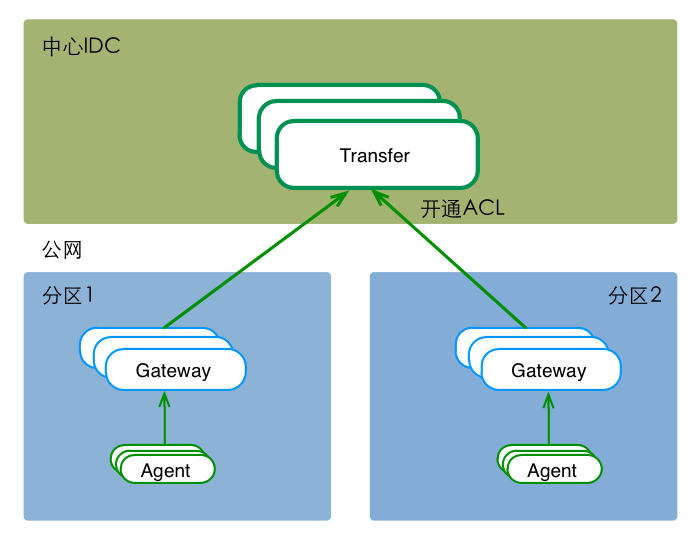
多IDC时,可能面对 “分区到中心的专线网络质量较差&公网ACL不通” 等问题。这时,可以在分区内部署一套数据路由服务,接收本分区内的所有流量,然后通过公网(开通ACL),将数据push给中心的Transfer。如下图,
数据存储
一般来说,监控系统要存储的数据量很大,写多读少,要求历史数据的查询要快速、高效。
在Falcon中,Graph组件负责绘图数据的存储。根据监控数据的特点,Graph在存储绘图数据时使用了Rrdtool。关于Rrdtool的概念,请参考其官网。
Graph组件从Transfer接收分片数据,然后将数据写入本地的Rrdtool。在数据每次存入的时候,Rrdtool会自动进行归档,归档策略可以由程序来定义。以一分钟的上报周期为例子,我们采用的归档策略是这样的: 历史数据保存5年;按照平均值、最大值、最小值进行采样,保存三份归档数据(尽量少丢失统计信息),归档策略定义如下:
// 1分钟一个点存 12小时
c.RRA("AVERAGE", 0.5, 1, 720)
// 5m一个点存2d
c.RRA("AVERAGE", 0.5, 5, 576)
c.RRA("MAX", 0.5, 5, 576)
c.RRA("MIN", 0.5, 5, 576)
// 20m一个点存7d
c.RRA("AVERAGE", 0.5, 20, 504)
c.RRA("MAX", 0.5, 20, 504)
c.RRA("MIN", 0.5, 20, 504)
// 3小时一个点存3个月
c.RRA("AVERAGE", 0.5, 180, 766)
c.RRA("MAX", 0.5, 180, 766)
c.RRA("MIN", 0.5, 180, 766)
// 1天一个点存5year
c.RRA("AVERAGE", 0.5, 720, 730)
c.RRA("MAX", 0.5, 720, 730)
c.RRA("MIN", 0.5, 720, 730)
用户查询某个counter时,Rrdtool会根据查询的时间段,选择合适的归档数据。比如,12小时以内的查询返回原始数据点,12小时至2天的 返回5m采样的点,1年的时间跨度返回1d采样的点。 Rrdtool的自动归档功能及数据读取的策略,很好的保障了绘图数据读取的速率。
Rrdtool归档采样时,会进行频繁的磁盘读写。这里,需要做特殊的优化。
数据查询
Query组件,向用户提供数据查询服务,接口形式为Http-Post。通过Query,用户可以查询指定时间段内、一批监控指标的绘图数据。接口的定义及使用介绍,见这里。
为什么要提供专门的数据查询组件、而不是直接从存储组件上拿数据?有两个原因。
- 监控数据按照哈希规则,分片存储在多个Graph实例上。Query提供一个统一查询入口、对外屏蔽数据分片的规则,用户查询数据时会变得更方便。
- 数据和用户操作之间,隔上一层Api,这是很常规的做法。通过这个Api层,可以方便的实现权限管理、流量控制等。
图表展示
展示监控数据的历史曲线,是监控系统的核心功能之一。Falcon提供了两种图表展示的方式: 动态查询 和 固定展示。动态查询,用于满足用户的临时查询需求。固定展示,为用户提供了定制绘图曲线的入口。
动态查询
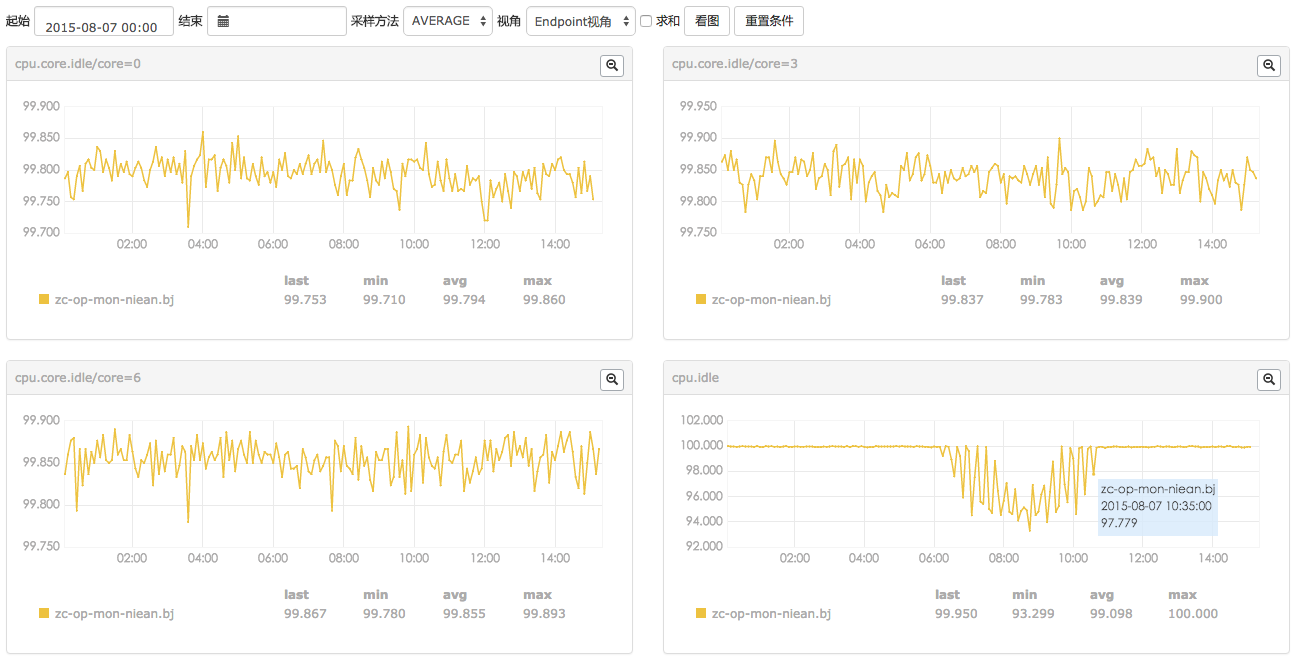
排查问题的过程中,用户经常需要临时性的查询某一个指标项的历史曲线;问题搞定后,用户可能就不在关注这个指标项了。这种情况下,用户可以进行动态查询,操作步骤为: 输入 endpoint 或 tag对儿,筛选出所有符合条件的endpoints; 再选中关注的endpoints,结合输入的metric/tags,查询出所有满足条件的counter; 选中endpoints + counters,就可以查看绘图曲线。
动态查询页面
动态查询的绘图曲线页面
固定展示
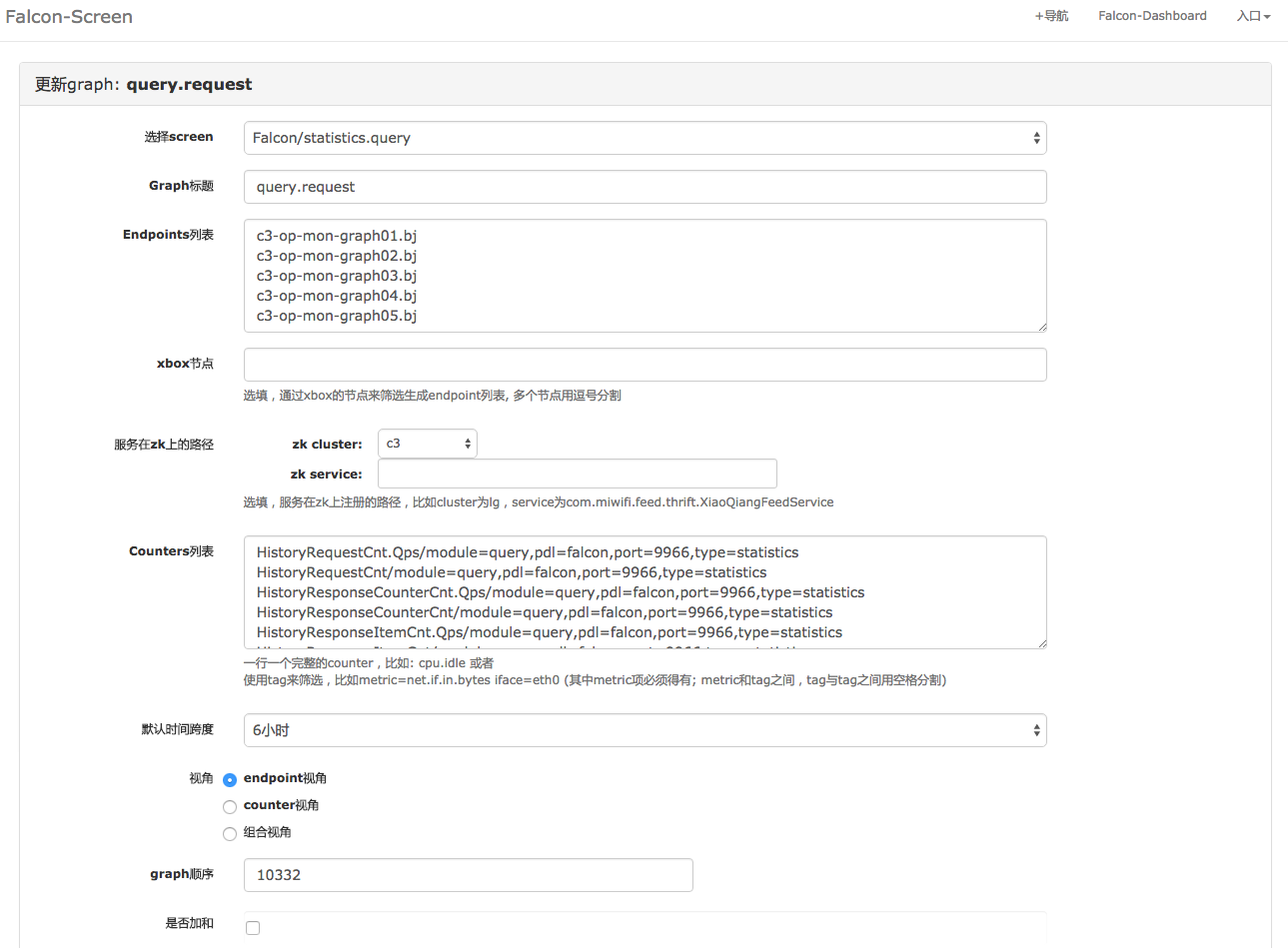
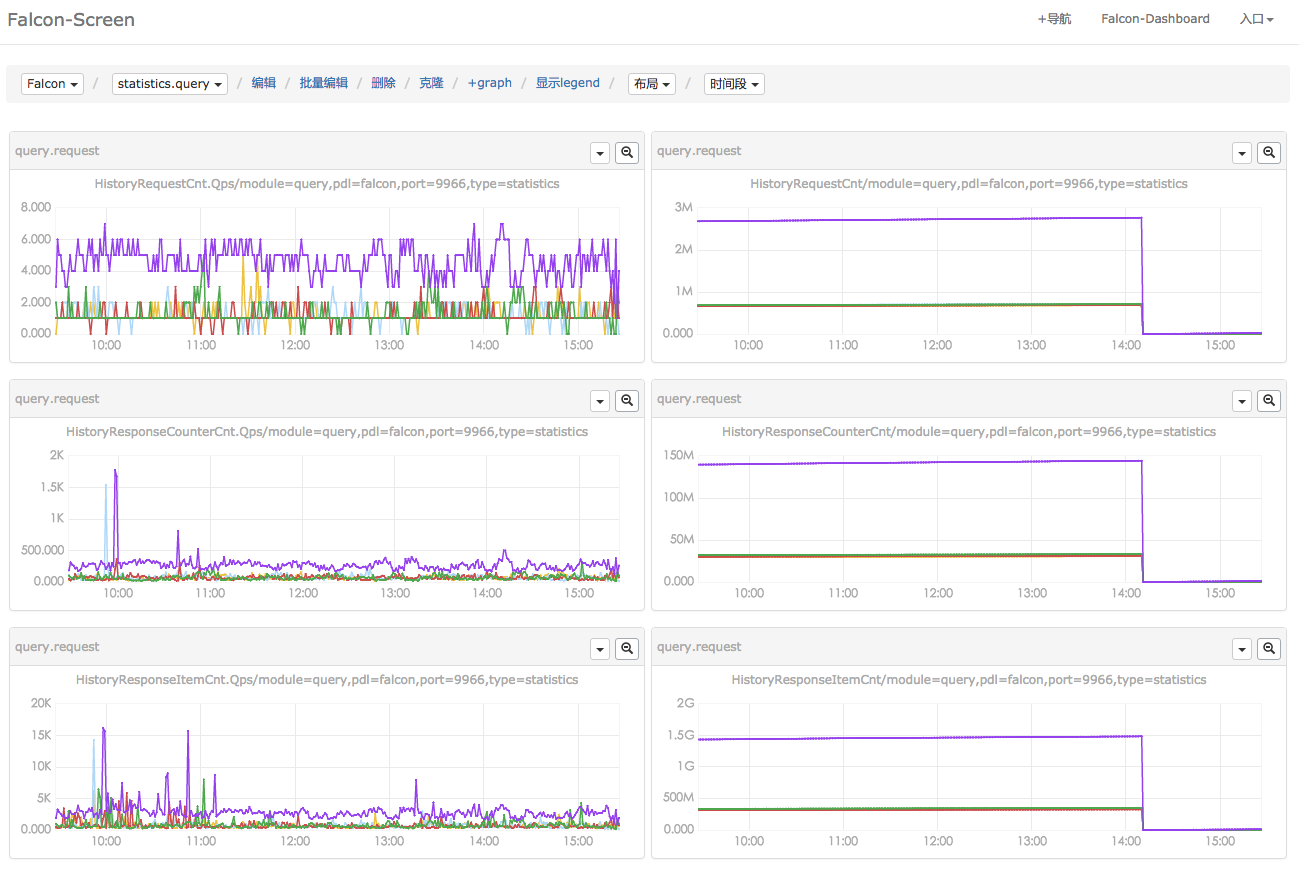
有一些监控指标,需要用户长期关注。这些指标,往往是确定的、有限的。这种情况下,用户可以使用Falcon提供的固定展示功能,操作步骤为: 定制Screen图表,一个Screen里面可以包含多个图表; 定制完成后,访问该Screen、查看图表。两步搞定,高度个性化,就这么流弊,呵呵。
配置Screen
查看Screen
整理一句,将绘图曲线展示和监控实体管理分开,很赞。这种逆天的设计,带来了很多灵活性,但需要在监控推广的早期逐渐培养用户的使用习惯、使之接受这种设计。看看大公司里的各种历史债、各种积重难返,深深觉着从零搞起一个项目很幸福。同时由衷的感叹,用户习惯的培养太重要了。
报警配置
监控报警的三要素,为: 监控数据的取值,判断条件,报警。报警动作、报警抑制、报警信息接收等,均包含在”报警”这一要素中,不详细展开。
配置报警策略,可以概括为: 筛选某个监控数据,设置判断条件,设置报警。监控数据,必须制定监控指标类型metric,另外可以通过tags进行筛选(endpoint是一个特殊的tag)。用表达式表示出来,如下:
//普适表达式
do strategy(){ //一条报警策略
each(metric=$M[, tag1=$T1, tag2=$T2, ...]) //筛选监控数据
if ( $Value -opt $Threshold ){ // 判断条件
alarm($Action, $Team){ // 报警
if (rules()) {
do $Action to $Team
}
}
}
}
引入机器分组和策略模板的概念,配置表达式进化为:
// 常用策略,基于机器分组和策略模板
each( endpoint in $HostGrp ){ // 机器分组
template2() extend template1 { // 策略模板
do strategy1-1(){
each( metric=$M1-1[, tag1=T1, tag2=$T2, ...] )
if(...) {...}
},
do strategy2-1(){
each( metric=$M2-1[, tag3=T3, tag4=$T4, ...] )
if(...) {...}
},
...
}
}
Falcon报警配置,支持普适表达式,也支持”基于机器分组和策略模板(简称为常用策略)”的配置。下面,分别介绍这两种配置方式。
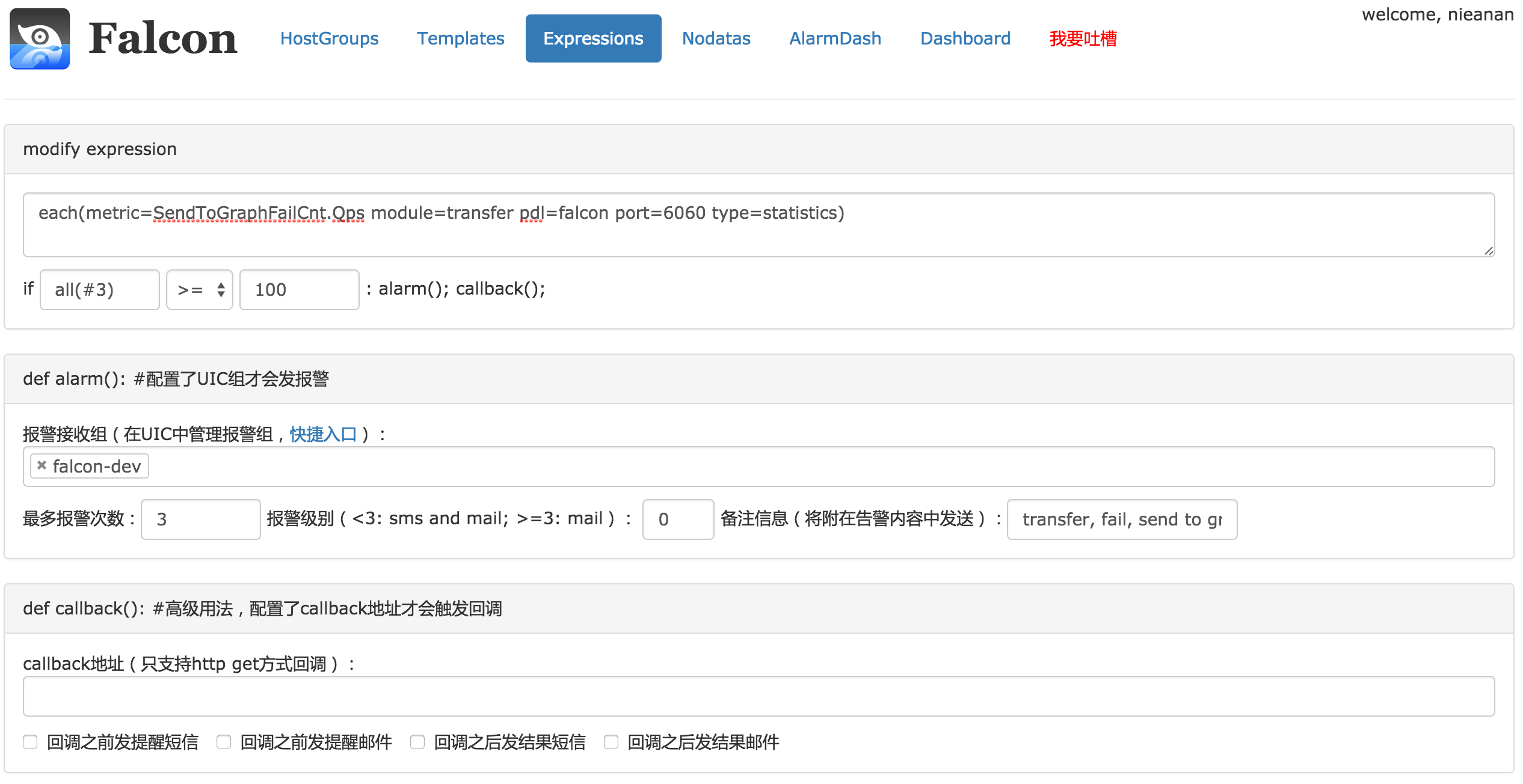
普适表达式
这是普适表达式的配置页面。一般的,endpoint不是机器名称时,使用普适表达式;endpoint为机器名时,建议使用常用策略。
常用策略
这是机器分组的管理页面,某个endpoint加入到某个机器分组中,就会自动拥有该分组所绑定的所有策略列表。此处可以和服务树结合,服务器进出服务树节点,相关的模板会自动关联或者解除。这样服务上下线,都不需要手动来变更监控,大大提高效率,降低遗漏和误报警。
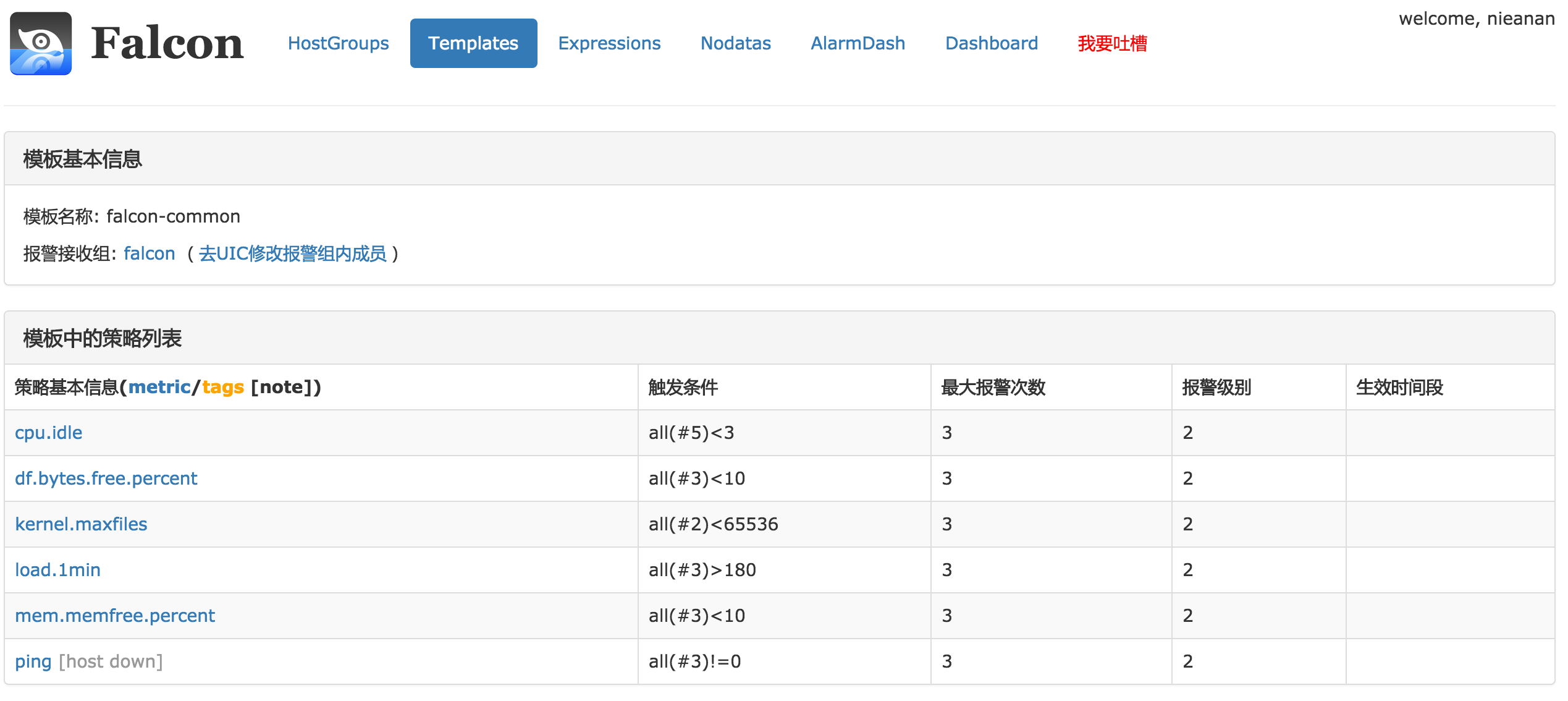
一个最简单的模板的例子,模板支持继承和覆盖,模板和机器分组绑定后,该机器分组下的机器会自动应用该模板的所有策略。
报警配置演进
报警配置 的优化过程,就是 不断优化监控数据的筛选、不断优化报警策略配置的过程。
1.普适形式
do strategy(){
each(metric=$M[, tag1=$Tag1, tag2=$Tag2, ...]) if ( $Value -opt $Threshold ){
alarm($Action, $Team){
if (rules()) {
do $Action to $Team
}
}
}
}
一个监控指标的数据,对应一个报警策略。有比这更通用的吗?不可能有! 有比这更难用的吗?估计也没有,因为大部分时候 用户都需要很多个配置才能搞定自己的需求。
2.机器分组
很多时候,监控实体都是机器、endpoint是机器名。这种情况下,endpoint是筛选监控数据的一个主要且通用的维度。
按机器名筛选监控数据,最直接的形式为:
do strategy(){
each( metric=$M, endpoint=$HostName[, tag1=$T1, ...])
if (...) {...}
}
为每个机器的指标项 进行报警配置,机器一多,配置就会很麻烦,配置的维护也需要很多人力。 很自然的,我们想对机器归归类、许多特征一致的机器被放在一个分组进行集中管理,于是抽象出机器分组hostgrp的概念;配置报警时,用机器分组代替机器,监控后台再把报警策略展开到分组内的机器上(机器和机器分组的关系需要在某个地方去维护)。这样,报警配置进化为:
each( endpoint in $HostGrp ){ // 机器分组
do strategy(){
each( metric=$M[, tag1=$T1, ...] )//这里,不需要再指定endpoint了
if (...) {...}
}
}
以机器分组维度,代替机器维度,能够大大减少报警配置的数据。但,要保留下普适方式,来覆盖小众(endpoint不是机器名的情况)的需求。另外,使用hostgrp还带来了一个意外的好处: 报警配置动态生效,机器加入某个分组、则能够获得此分组上的报警策略,机器移出某个分组、通过原分组获取的报警策略也将被移除。
3.策略模板
完成一个监控需求,往往需要多个报警策略,需要几个就要配置几个,有点麻烦。为了提高配置效率,把相关的策略绑在一起、构成一个策略组、形成一个新的概念: 策略模板。有个策略模板,配置形态也就发生了变化,原来是一次只能配置一条策略,现在可以在一个策略模板里面 一次配置多条策略了,如下:
template { // 策略模板
do strategy1(){ // 策略1
each( metric=$M1[, endpoint=$E1, tag1=T1, tag2=$T2, ...] )
if(...) {...}
},
do strategy2(){ // 策略2
each( metric=$M2[, endpoint=$E2, tag3=T3, tag4=$T4, ...] )
if(...) {...}
},
...
}
上面的配置形式,已经很简化。如果策略模板能够被复用,将进一步简化 策略模板的配置。复用,以继承的方式实现;有继承,就有覆盖,来满足”策略模板中的部分表达式需要特殊化”这个需求。生生的,又迈出了一个大步子,现在配置形式如下:
template2() extend template1 { // 继承
do strategy1-1(){ // 覆盖
each( metric=$M1-1[, endpoint=$E1, tag1=T1, tag2=$T2, ...] )
if(...) {...}
},
do strategy2-1(){ // 新增
each( metric=$M2-1[, endpoint=$E2, tag3=T3, tag4=$T4, ...] )
if(...) {...}
},
...
}
打完收工。报警配置的一个终态如下,保留普适表达式、结合机器分组和策略模板的概念,既方便使用、又照顾小众需求。
// 普适表达式
do strategy(){
each(metric=$M[, tag1=T1, tag2=$T2, ...])
if(...) {...}
}
// 常用策略,基于机器分组和策略模板
each( endpoint in $HostGrp ){ // 机器分组
template2() extend template1 { // 策略模板
do strategy1-1(){
each( metric=$M1-1[, tag1=T1, tag2=$T2, ...] )
if(...) {...}
},
do strategy2-1(){
each( metric=$M2-1[, tag3=T3, tag4=$T4, ...] )
if(...) {...}
}
...
}
}
这里有几点,需要特别指出:
- 继承&覆盖这两个特性,只发生在策略模板上。监控系统的机器分组,不存在所谓的继承&覆盖特性
- 监控系统的机器分组,是一级的扁平结构,机器分组之间无继承关系。很多公司,机器管理都是借助”服务树”进行的。在设计监控系统时,他们把服务树当成稳定的、可依赖的基础设施,因此,把服务树节点当做机器分组来使用、通过服务树节点的上下级关系实现继承和覆盖。而实践中,服务树是可能发生剧烈变化的,甚至会有多棵树的出现,这时监控系统就只能死翘翘了。一种可行的改造方案是: 将服务树各节点扁平化为一级节点,去掉节点之间的上下级关系、只保留其机器分组管理的特征;转而,将继承和覆盖的属性赋予策略模板。
结束语
总的来说,Falcon在理念、实现上都是非常先进的,领先传统厂商至少一代。再次整理下这些Features:
- 数据收集,不需要预定义、提供了完善的数据收集器,方便用户自己push数据。从而,监控可以做到不过分关注数据采集
- 绘图展示,灵活而又能定制
- 实时报警,配置高效而灵活,使用tag过滤机制、使用hostgrp管理实体、使用template管理策略
- 机器分组,设计成一级扁平结构,使得监控系统可以适应CMDB的结构变更
- 其他方面,纯粹的平台化理念、成功的用户习惯培养、良好的工程控制,等等
参考资料
本文参考、整理了小米Open-Falcon的部分内容。