监控系统解决了基本的业务需求后,开始逐步考虑自身的高可用问题。大体,可能会有如下三种演进阶段。Falcon目前正在向第二阶段演进。
第一阶段:集中式部署
监控系统的所有核心组件,都部署在一个中心IDC;区域IDC,通过Hbs-Proxy来同步配置信息,通过Transfer-Proxy来上报监控数据。如下图。
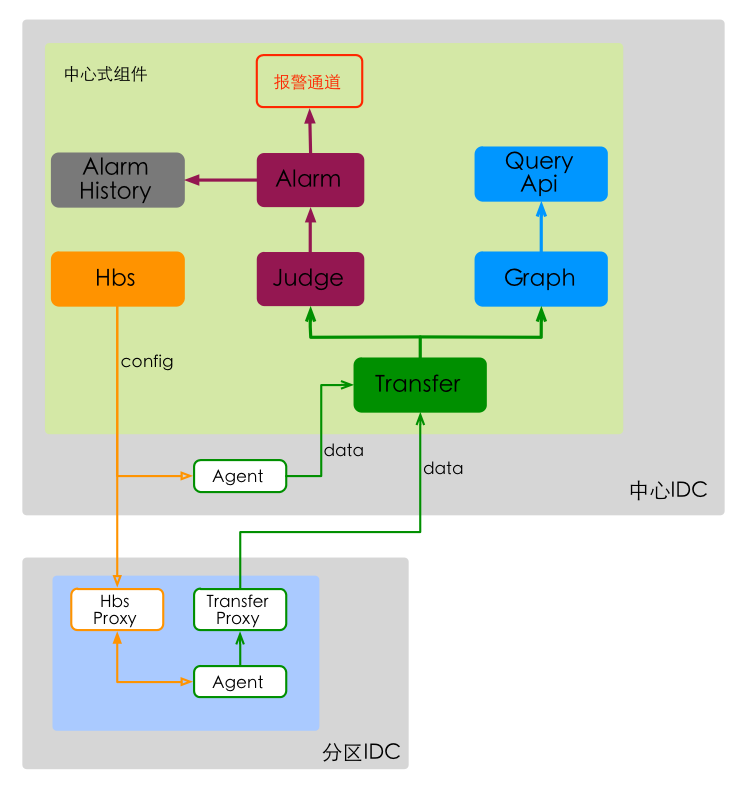
集中式部署,存在机房单点故障风险。为了防止中心机房故障,可以做双机房热备,此时资源消耗会double。
优点
- 监控系统各组件易于部署,易于维护
- 数据及状态信息集中存储在中心IDC,有利于UI展示、数据聚合等数据消费活动
缺点
- 跨IDC传输数据时,数据丢失的风险高,监控服务可用性低(约99.95%)
- 跨网传输监控数据,带宽成本高(监控占用了约30%的内网带宽)
第二阶段:报警高可用
监控的核心价值,在于及时发现故障,因此,需要保障报警链路的高可用。当业务对监控报警提出更高的可用性要求时,考虑将报警链路下放到区域IDC、消除跨IDC网络影响;历史数据存储、报警状态存储等等的状态信息,依然存储在中心IDC。部署架构,如下图。
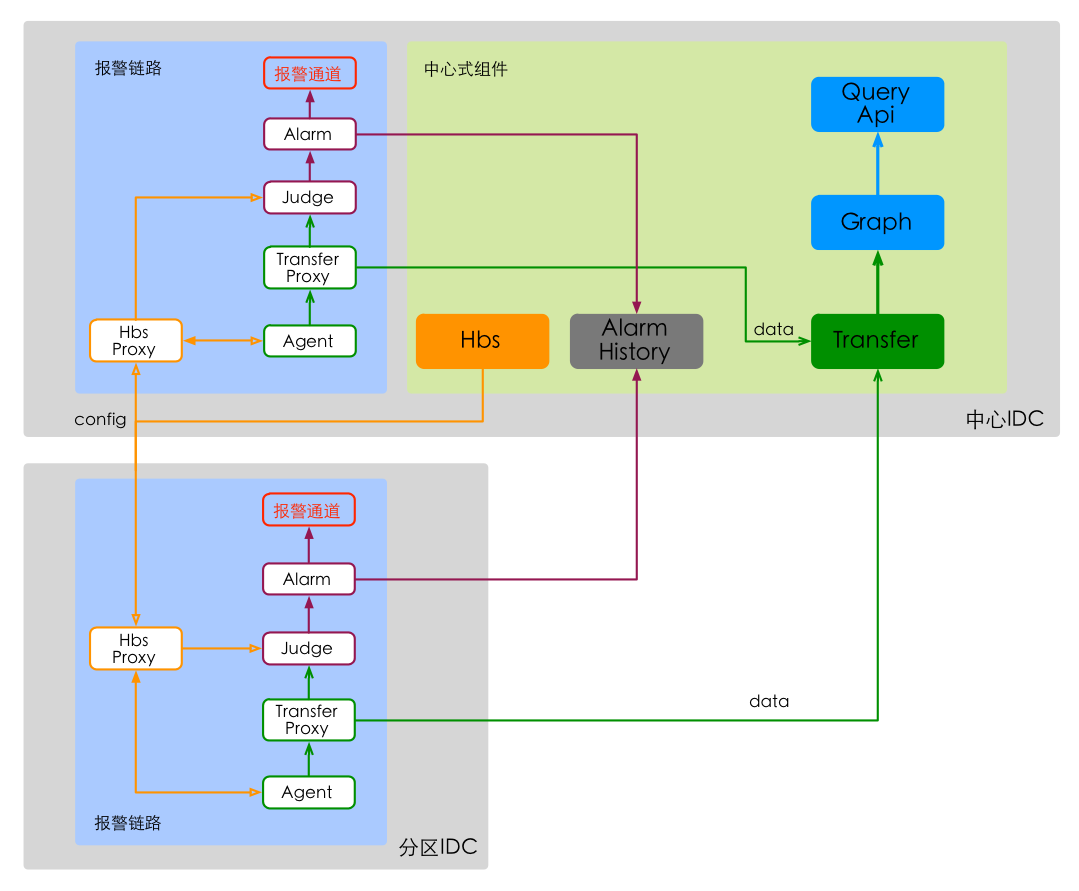
较之集中式部署,第二阶段,报警链路下放到了各个IDC,数据及状态信息仍然集中保存在中心IDC。部署架构上,监控报警链路和历史数据存储链路,完全分离。
优点
- 报警链路本地化,实时报警的可用性提高1+个数量级
- 数据及状态信息集中存储在中心IDC,有利于UI展示、数据聚合等数据消费活动
缺点
- 部署变复杂,运维成本提升
- 网络安全成本提高,跨网操作时,Proxy和RealServer之间需要ACL控制
- 跨网传输监控数据,带宽成本高
如果不考虑带宽成本,第二阶段的部署架构已经可以满足业务需求,虽然这种架构看起来略微丑陋。
第三阶段:区域IDC自治
分IDC自治,将监控系统各组件均下放到各IDC,每个IDC都具有独立的监控能力,实时报警、历史数据的可用性均达到最高。在中心IDC,提供一个统一的Portal,对用户,屏蔽监控系统分IDC部署的细节。如下图,
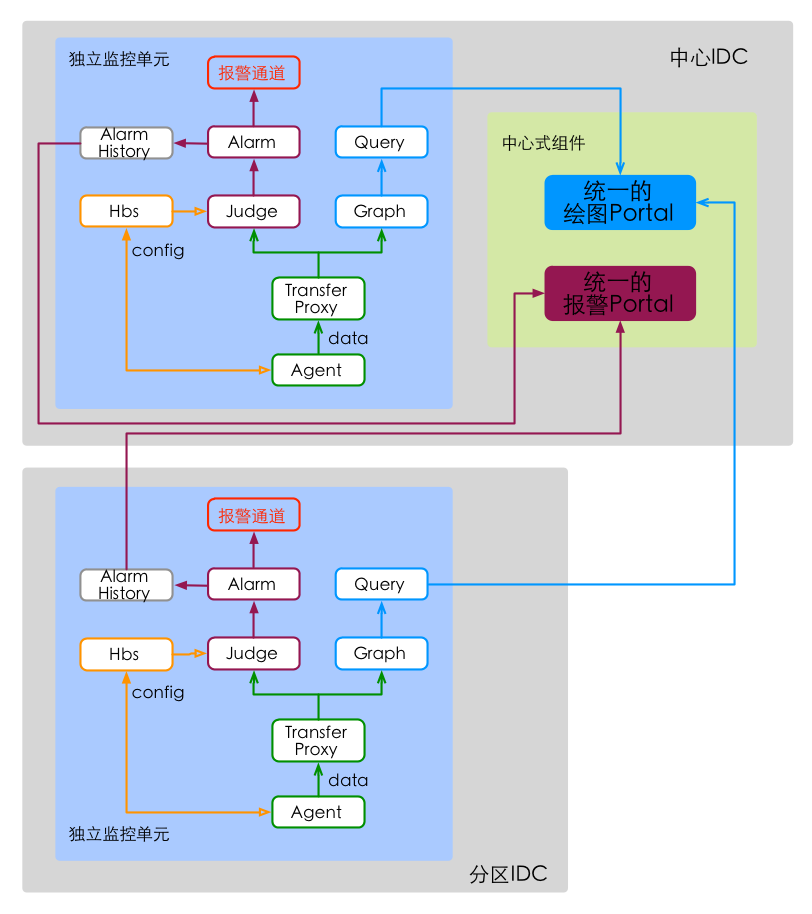
中心统一的Portal,无状态,可以较容易的实现高可用。用户在Portal的每次请求,可能会受到当时网络链路的影响,但不影响最终可用性。
优点
- 监控分区自治,报警和绘图的可用性,达到了理论上限
- 数据分区存储、不跨网传输,节省了网络带宽
缺点
- 分区部署完整的监控服务,部署和维护成本最高
- 统一的Portal,需要耗费更多人力,来开发和维护
总结
以上三个阶段的部署演进,取决于如下业务特点:
- 公司内网可用性: 不可靠的跨IDC内网专线,不可靠的内网接入
- IDC与业务特点: 存在这样的场景,即某IDC接入内网的链路异常、但对外仍然可用
- 业务需求: 为获取少量的监控可用性提升(万分之一量级),愿意支付double、甚至triple的成本
网络环境、业务需求、成本(资源&运维&开发等),最终决定了监控系统的部署架构。特别的,网络环境是可以优化的环节;网络链路可用性的提升 可以节省大量的应用层成本,从公司层面来讲 是值得投入的。