很高兴和大家一起分享下 滴滴监控系统 DD-Falcon 近期的一些进展

目录结构
今天分享 主要包括如下几个部分 (技术架构、产品形态):
- DD-Falcon的系统架构
- DD-Falcon相比Open-Falcon的一些改进
- 目前遇到的问题
- 将来的几个规划
系统架构
DD-Falcon脱胎于开源监控系统Open-Falcon。Open-Falcon是小米运维团队2015年开源的一款监控产品,目前已应用在 小米、美团、滴滴、快网、JD等众多互联网公司,Open-Falcon的详情可参见这里。
在介绍DD-Falcon之前,我们先介绍下Oepn-Falcon的系统架构。
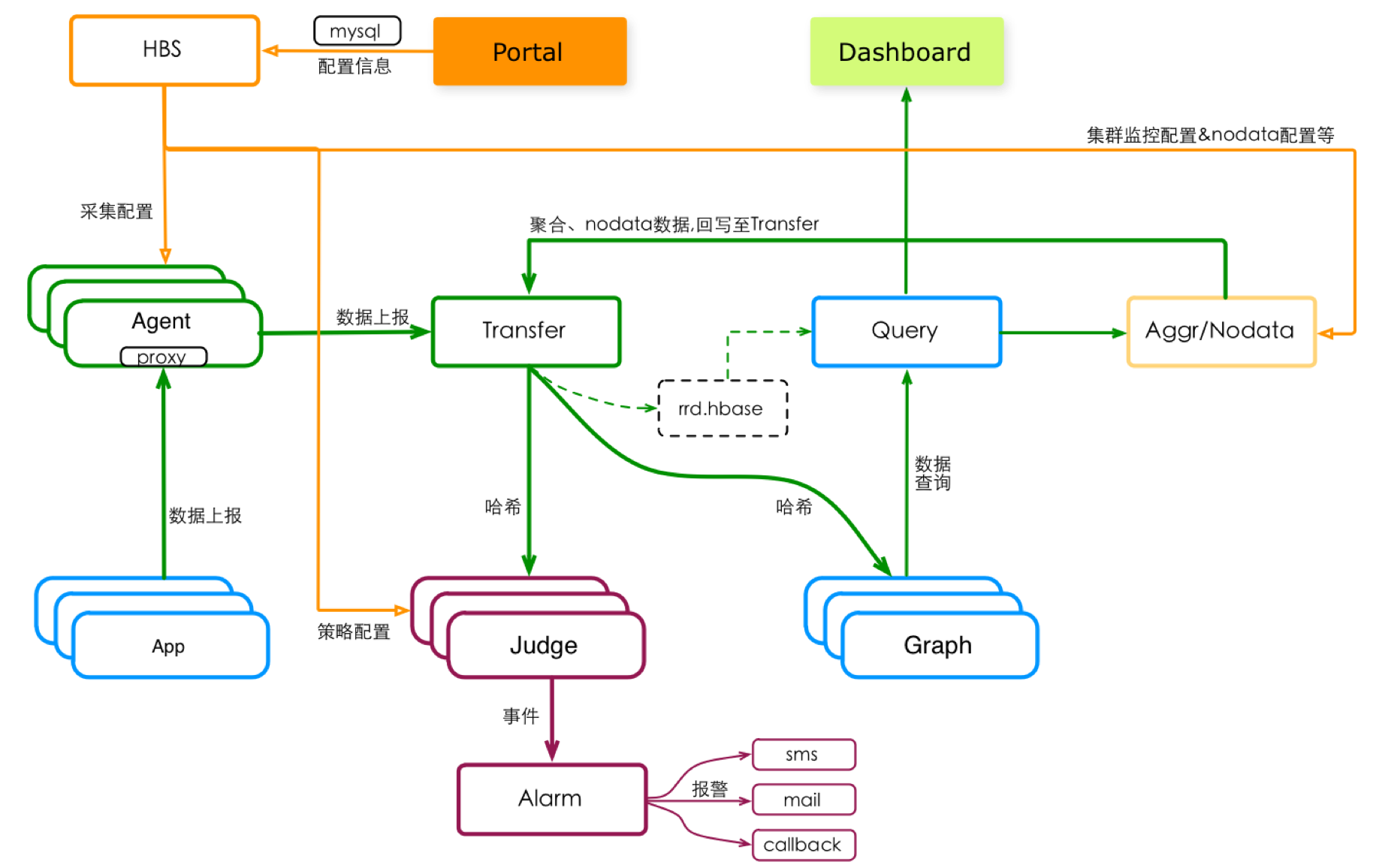
上图是Open-Falcon(后简称OF)v0.1的典型架构(v0.2有些许调整)。橙色的线代表了配置流,绿色的线代表了数据流,紫色的线代表了报警链路。
OF配置流
配置信息,由用户产生,并逐级应用到各个组件,主要流程是:
用户 –> UI(Portal) –> 配置中心(HBS) –> 采集(Agent), 报警(Judge), 计算(Aggr/Nodata)
其中,HBS原意为心跳服务、后逐步发展成为配置中心。
OF数据流
监控数据的整个生命周期,分为 采集、收集、分发、存储、消费等几个环节。
Falcon-Agent是主要的采集器和收集器,它被部署在每个单机实例上(物理机或者容器),采集本机基础信息(如CPU、内存、磁盘等,自动采集)、 本机部署的应用程序信息(如端口信息、进程信息等,由用户配置),同时也会作为代理、接收 本机应用程序 主动上报的业务监控数据(如 App埋点&内存统计产生的Metrics数据 等)。Falcon-Agent将 自己采集 或者 收集的监控数据,主动推送 给 Transfer。
Transfer是数据分发组件,将接收到的监控数据 一式两份、分别发送给 数据存储组件Graph 和 实时报警组件Judge。Graph和Judge都采用一致性哈希做数据分片,以提高横向扩展能力。Transfer按照哈希规则,将监控数据 主动推送到 固定的分片上去,对数据生产者 屏蔽分片细节。
Graph提供数据存储能力。Graph底层使用rrdtool做单个指标的存储,rrdtool的特点 决定了 单个指标存储空间固定、数据自动降采样,这个特点很适合 监控热数据的存储。Graph在应用层对rrdtool做了写优化(缓存, 分批磁盘写等),使得一个Graph实例能够处理 8万+/秒的数据点写入频率。
Graph一般由多个实例构成集群,不同实例存储不同的监控数据。为了屏蔽存储集群的分片细节,提供了Query模块,实现了和Transfer一样的一致性哈希分片逻辑,对数据消费者屏蔽存储分片细节。Transfer + Graph + Query 构成了功能完整、横向可扩展、技术门槛低 的分布式时间序列化数据存储系统,这是Open-Falcon的核心竞争力所在。
存储之上,长出了用户最常用的 监控看图功能,对应到上图中的Dashboard模块。另外,集群聚合模块Aggr、数据中断报警模块Nodata 都会消费 存储的数据。
OF报警链路
Judge和Alarm两个模块构成了OF的报警链路。Judge 由Transfer上报的 监控数据驱动,结合用户配置的报警策略,实时计算、产生报警事件。Alarm组件对报警事件做一些收敛处理后,将最终的报警消息推送到各报警通道。OF的报警,是由监控数据驱动的,没有数据上报 就 不会报警。
以上大概介绍了下OF的系统架构。相比OF,DD-Falcon(下面简称DF)的主要组件 结构如下。
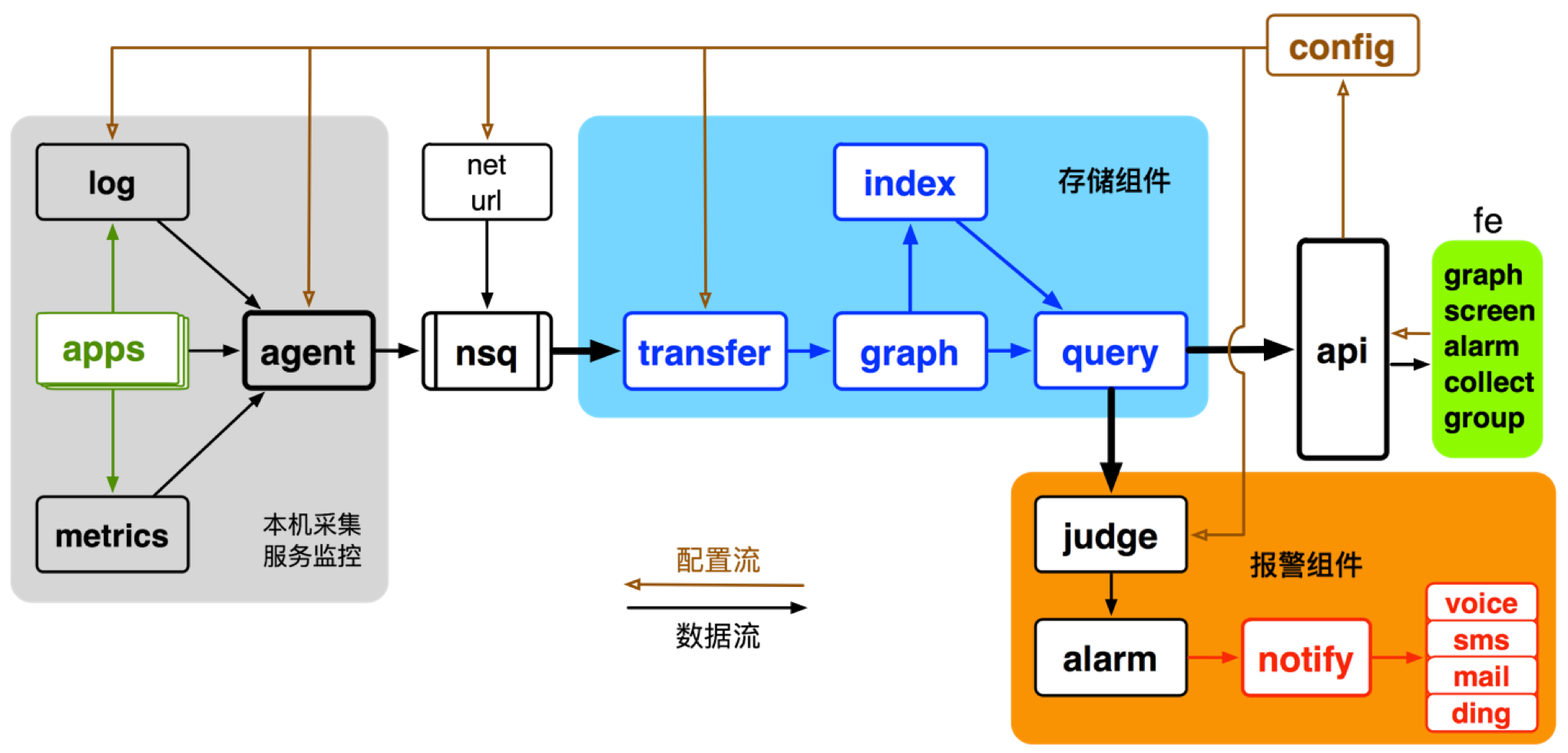
配置流由棕色曲线表示,数据流由黑色曲线表示。
配置流从右向左,依次为:
用户 –> 配置(fe/api) –> 存储(config) –> 生效: 采集(agent/log/net/url), 清洗(transfer), 报警(judge)
数据流从左向右,依次为:
服务(apps) –> 采集 –> 收集 –> 清洗 –> 存储 –> 消费: 报警, 看图, 第三方
DF的配置流,与OF的相似,不再赘述。DF的数据流,核心存储部分 继续使用OF原生组件(transfer + graph + query), 同时在数据采集、清洗、报警等方面做了调整。
DF采集
DF的采集 覆盖了 机器指标(如CPU、内存、磁盘)、应用指标(如端口信息、进程信息)、业务指标(如rps、error_ratio、latency)等。
业务指标,主要是通过 log本机日志实时分 和 metrics业务统计 获取的。log分析方式是历史沿袭,比较方便、但资源消耗不可控,正在被逐步弱化。
metrics是类似开源 statsd 的解决方案,通过业务代码埋点 将状态数据(rpc调用质量、计数等)上报到本机metrics-agent,再经由metrics-agent周期性的 统计聚合,将最终的业务统计数据上报到 本机agent上(agent充当了收集器)。
metrics对于无状态的服务非常友好,正在逐步成为主流(有状态的服务可以在 应用内存中 做统计计数,正如OF一样)。
机器指标、应用指标的采集主要是由 本机上的agent(DF-Agent)完成的,也会自动采集、主动上报数据,与OF相似,不再赘述。
DF收集
为了应对 上报峰值、网络抖动等问题,DF增加了 nsq数据缓存队列,agent上报的监控数据 先被q到nsq、再由分发组件消费。nsq按照 服务单元(su) 划分topic。
DF清洗
在nsq数据缓存 和 存储之间,增加了一个数据清洗环节,实现了容量控制、垃圾数据过滤 等机制,用于监控系统的自我保护。后面会详细讲述。
DF存储
DF复用了OF的 transfer + graph + query三个组件,在此基础上 将数据索引模块index独立出来(OF使用mysql做简单的查询索引)。索引信息,是在指标写入graph时同步生成的,可以满足 分级查询 的需求。索引模块是DF 对OF的主要改进之一。
DF消费: 看图
看图,是长在存储上的一个功能。DF的支持 动态看图、临时图、监控大盘等产品形态,支持同环比看图,支持灵活的聚合展示,等等。
DF消费: 报警
与OF相比,报警变成了存储模块的一个下游,不再拥有独立的数据上报链路。
judge模块从config处获取报警配置,然后按需 从存储组件 拉取 命中的指标数据,进行 实时报警计算,产出报警事件。alarm模块做报警收敛处理,并将最终的报警通知交给 报警通道服务notify 处理。notify支持多种报警通道,包括钉钉、语音、短信、邮件等。
DF将 报警数据的获取方式 由推变拉,给报警判断 带来了巨大的灵活性。报警方式由推变拉是DF对OF的另一个主要改进。
DF消费: 第三方
DF的监控数据完全开放, 供各个业务线使用。特别的,不同的业务场景 看图功能的产品形态 差异较大,开放数据、让用户自定义 很可能是监控平台后期的大趋势。我们正计划结合Grafana,给一种低成本的、较通用的 个性化看图解决方案。
以上是对DD-Falcon的一个简单介绍。下面重点聊一下 相比Open-Falcon,我们的一些改进。
主要改进
DD-Falcon相比Open-Falcon,主要有如下改进:
- 监控数据按服务单元分类
- 增加垃圾数据清洗
- 分级索引
- 精简RRA
- 巡检大盘支持同环比
- 重组看图首页
- 报警数据获取由推变拉
- 干掉报警模板
- 重新定义nodata
下面,针对每一项做下详细介绍
1. 监控数据按服务单元分类
每一个监控数据点,不管是机器指标、应用指标还是业务指标,都必须标明 所属的 服务单元su。
服务单元定义:
su = ${cluster}.${uniq-service-name}
如 gz01.falcon-query 代表 “falcon-query服务 的gz01 部署集群”(gz01为逻辑机房标识)
监控数据点举例:

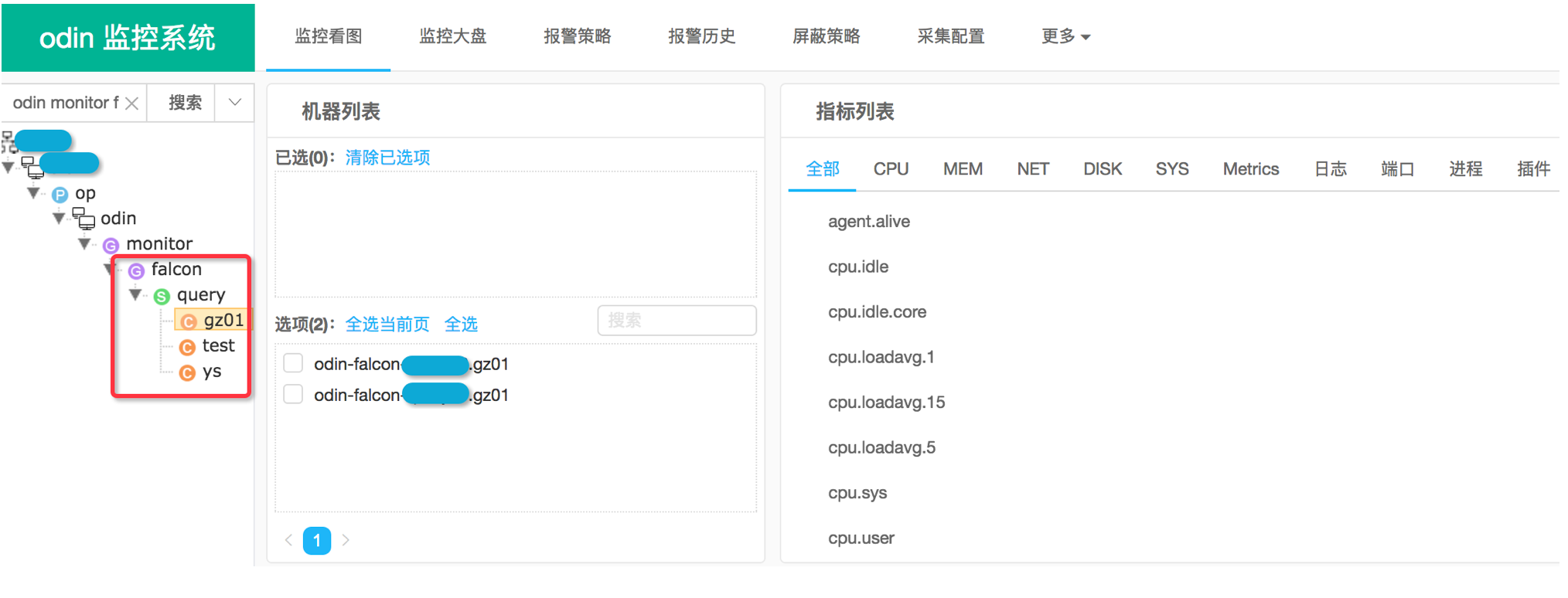
强制su的约束,给后续的 缓存分片、数据清洗、报警、看图展示等 增加了一个常用的、可信的 服务维度。如,看监控图时,服务树与su严格对应,查看某个服务的监控图会很方便:
2. 增加数据清洗
DD-Falcon继承了OF 允许用户上报自定义数据的功能,带来了很多便利,同时 也给带来了垃圾数据的困扰。一些用户,将 traceid、errmsg等非tsd属性的数据,直接上报到了监控系统。另外,一些通用的中间件采集,也可能会将orderid等信息上报到监控系统。
有几次,我们不得不 通过清空历史数据的方式 来清理垃圾数据,监控系统表示受伤很深。垃圾数据经常要事后发现、人肉拦截,开发人员表示无法接受。为此,我们在nsq到存储集群间,增加了一个垃圾数据清洗环节,如下图所示位置
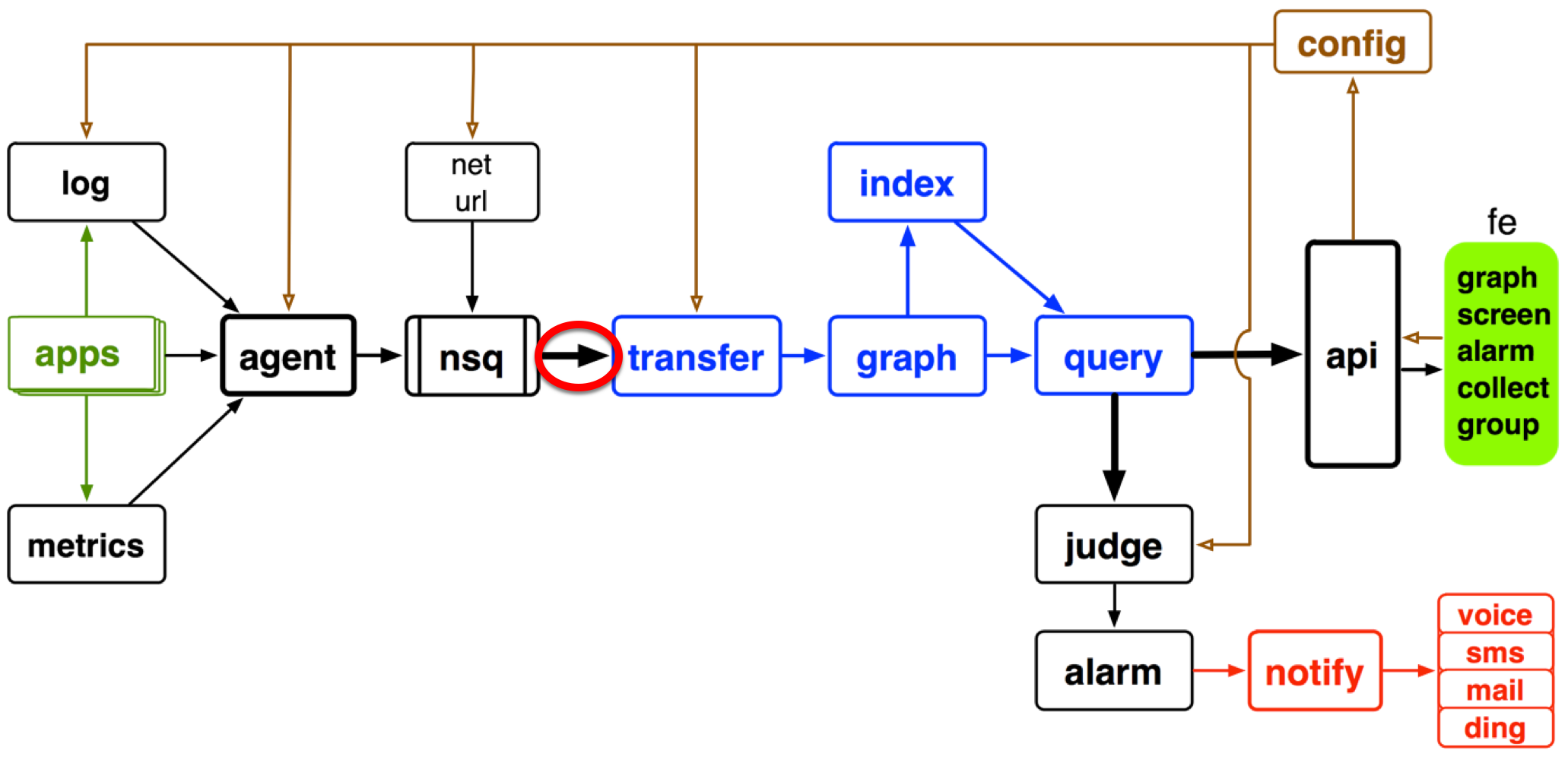
每个监控数据点,都有几个固定的维度,包括 su、metric、tagk(如host、trace)、tagv,垃圾数据一般能在某一个维度上有所体现。下面的例中,垃圾数据就体现在 tagk=trace这个维度上。另外,垃圾数据通常较”明显”,通过简单的字符串匹配就能识别出来。
因此,我们的 数据清洗 主要集中在如下两个方面:
- 清洗维度: 服务单元su, 指标metric, tagk, tagv, metric/tagk
- 清洗方式: 字符串 相等, 前缀, 后缀, 包含
举例: 垃圾指标,及对应的清洗规则:

从目前的经验来看, 95%的清洗规则, 是通过 tagv前缀匹配 实现的
垃圾数据,可以通过 服务的 指标总量、单位时间指标增量、指标最新上报时间 等方式被定位,再结合简单的学习算法,就能自动生成过滤规则。最终,数据清洗会变得自动化。
3. 分级索引
DD-Falcon根据滴滴的用户习惯,实现了一个多级索引结构,让用户看图、数据读取更灵活。
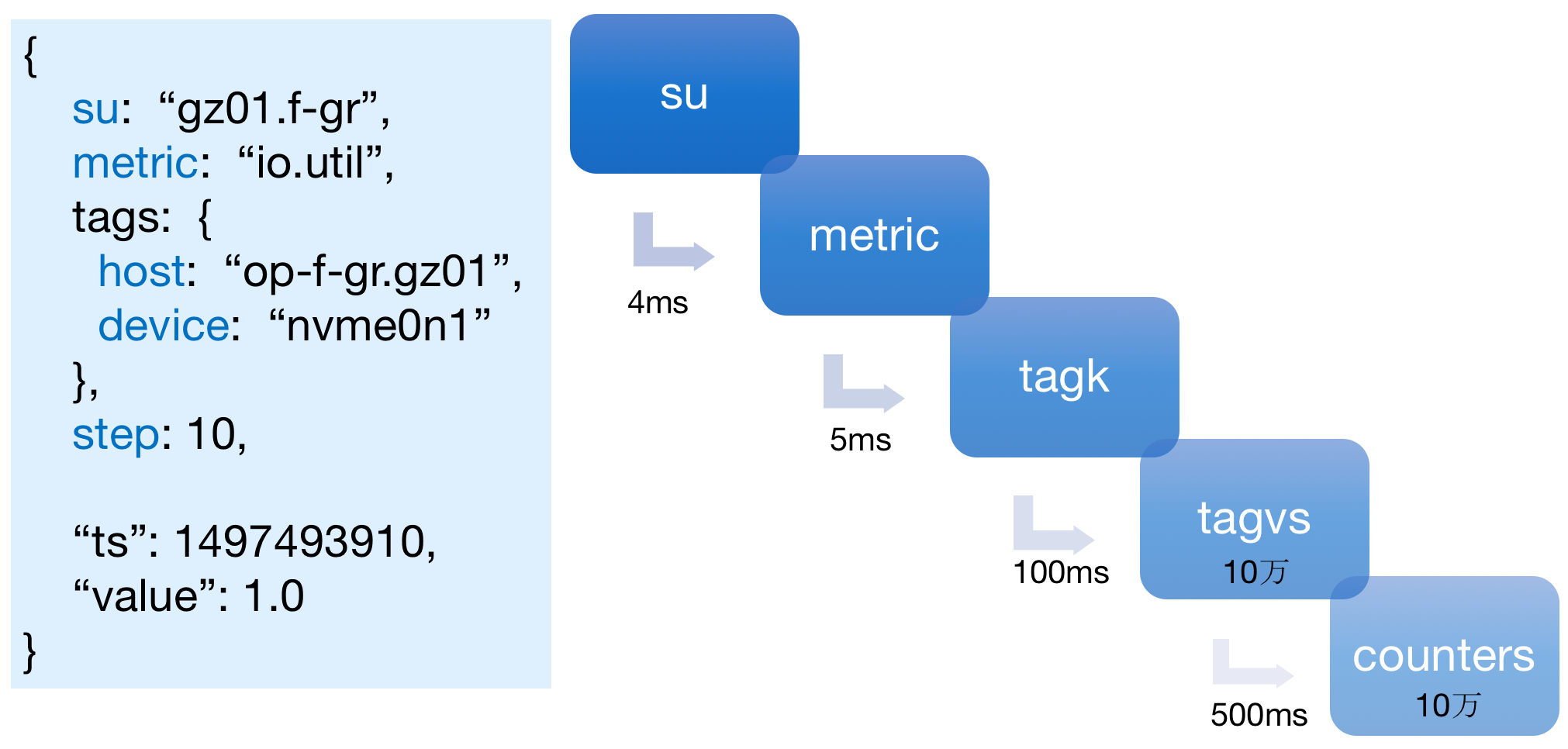
如上图,左侧是 一个典型的监控指标,右侧是分级索引。用户 首先 选择要查看的服务,然后选择一个监控指标,最后设置 每个tagk的取值;经过这几步,用户就能拿到一系列备选曲线,并能够从中选择自己想要的曲线。整个过程,耗时不超过1秒,用户体验很好。
我们采用全内存的方式,实现了上述结构,性能数据如下:
- 1000万指标: 构建耗时30s, 消耗内存2GB
- 1亿 指标: 构建耗时5min, 消耗内存17GB
之所以选择内存方式,是 快速重建索引 的需要(早期 垃圾数据预防未到位,业务上要求10min内恢复服务)。当前没有计划做分片,原因在于: ①廉价的高内存主机已经很普遍,②内存消耗优化后预计还可以降低50%
灵活的索引,可能是 监控数据查询语言的雏形,后续还会继续进化。
4. 精简RRA
DD-Falcon只保留了均值降采样、干掉了最大值&最小值降采样,原因在于 最大值&最小值降采样使用率过低。DD-Falcon的高精度数据会保存8天,这个是同环比报警的需要。
精简后的RRA,如下图所示:

按需调整rra后,节省了更多的磁盘资源
5. 巡检大盘支持同环比
这是一个产品形态上的完善,最终将回馈到Open-Falcon社区。大部分公司,业务都是以 1天 或者 1周 为周期变化的(节假日除外),因此我们的同环比只支持1天和1周两个选项。
一个典型的每日巡检大盘,如下图
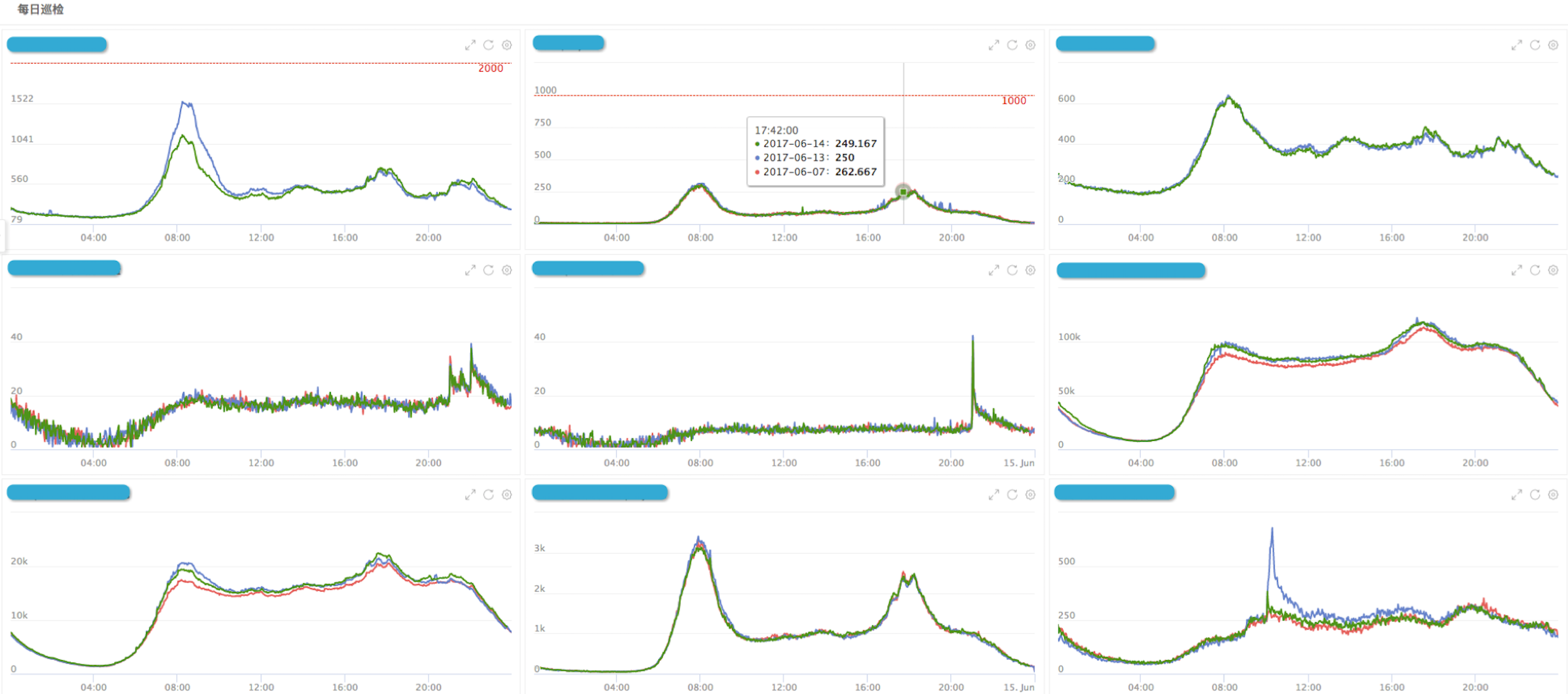
其中,绿线代表今天、蓝线代表昨天、红线代表1周前,同环比波动一目了然。目前,60%的巡检大盘,都是同环比。
6. 重组看图首页
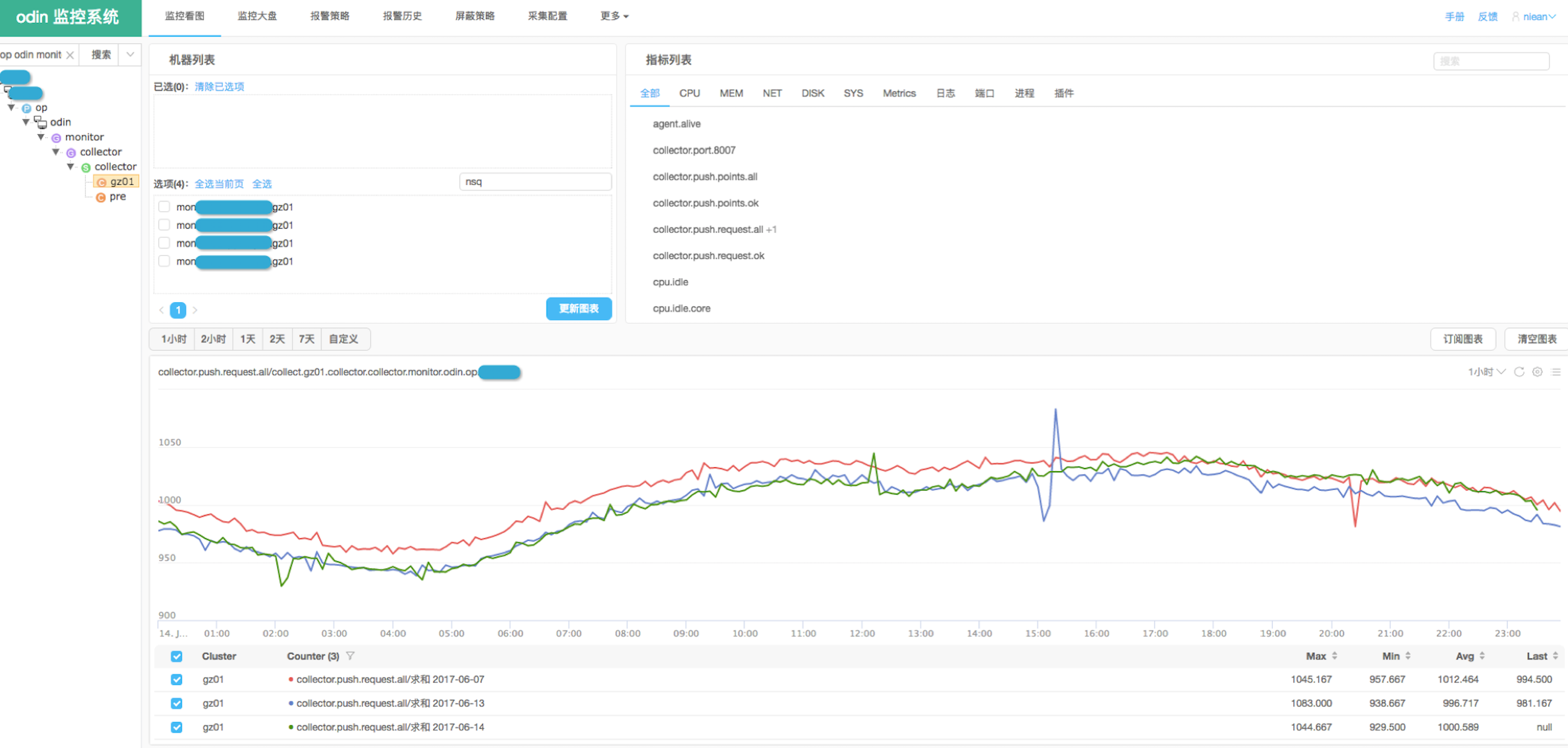
我们的 监控数据已经带上了服务单元标识(之前已经有了机器标识),我们的 索引已经支持分级查询,因此我们将 首页看图的步骤约定为:
服务单元 –> 节点 –> 机器 –> 指标分组 –> 看图 –> 订阅大盘
指标分组,是将用户常用的、类似的指标归为一个tab,以方便查询。
这是一个比较定制的功能,不一定适合社区环境。最终的首页看图,效果如下图:
7. 报警数据获取由推变拉
DD-Falcon的报警数据获取,调整为 judge主动从存储拉数据。整个报警过程,变为:

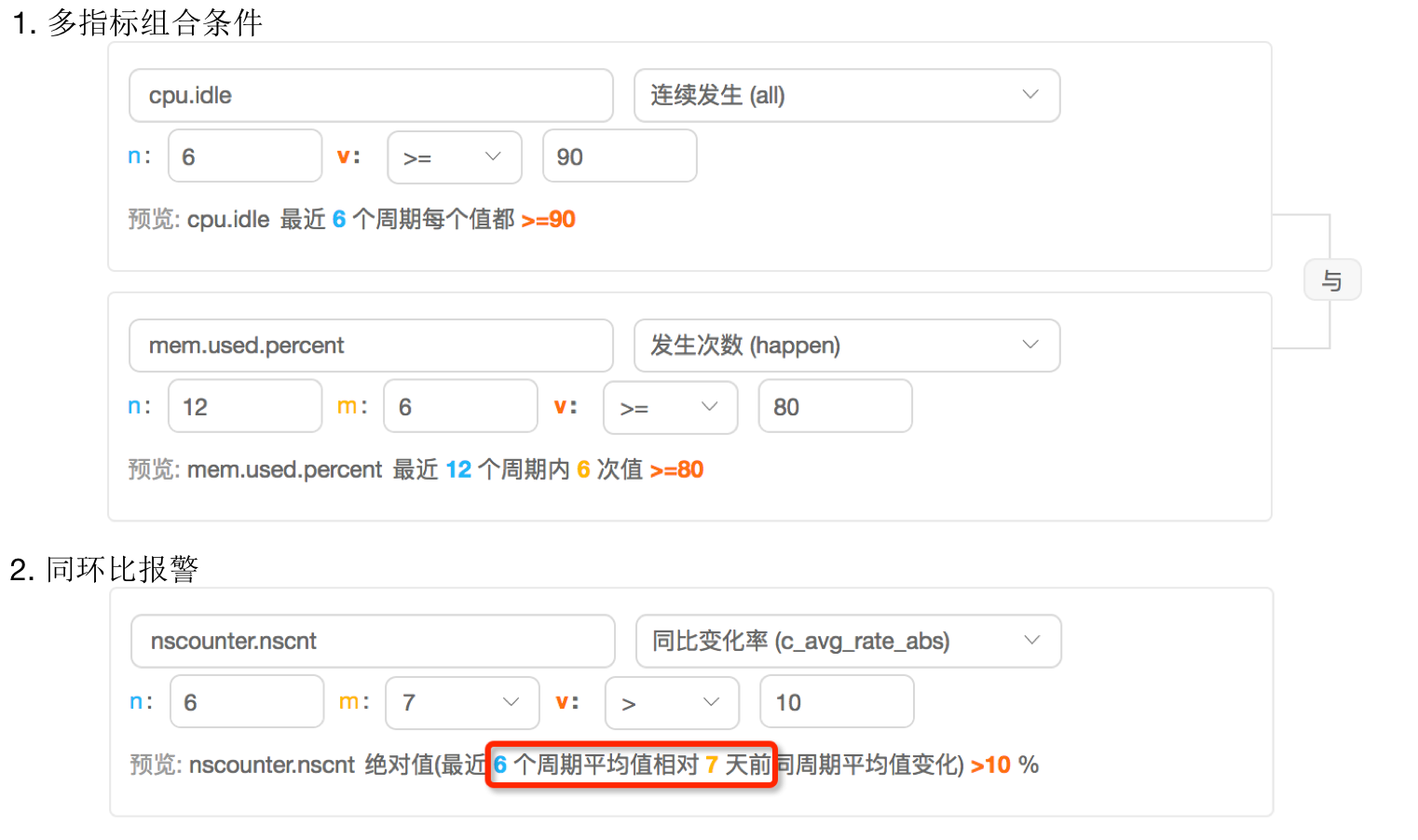
拉数据更灵活,可以实现多种判断条件: 多条件组合判断, 同环比报警, 集群报警 等。
下图是DD-Falcon的报警配置页面,
补充一句,在智能报警时代,拉数据的方式 必将全面取代 推数据的方式,我们也算是提前做了过渡。
8. 干掉报警模板
OF为了简化报警策略的管理,继承了zabbix报警模板的衣钵。从最后的效果看,模板并没有明显降低管理成本,却带来了很高的学习成本,特别是模板间的继承、覆盖云云 最后连维护者都搞不清了。
因此,DD-Falcon干掉了模板的概念,每个报警配置就是一条策略,策略和策略之间没有关联关系,策略借助服务树的节点父子关系实现 继承和动态生效,借助节点排除实现特例。虽然有可能增加管理成本,但大大降低了用户的学习成本,这个收益我们更关注。
如下是对典型场景下 使用报警模板与否 的利弊分析,关注的童鞋可以了解下

9. 重新定义nodata
DD-Falcon重新定义了nodata报警的业务场景,也简化了产品形态。具体,如下图
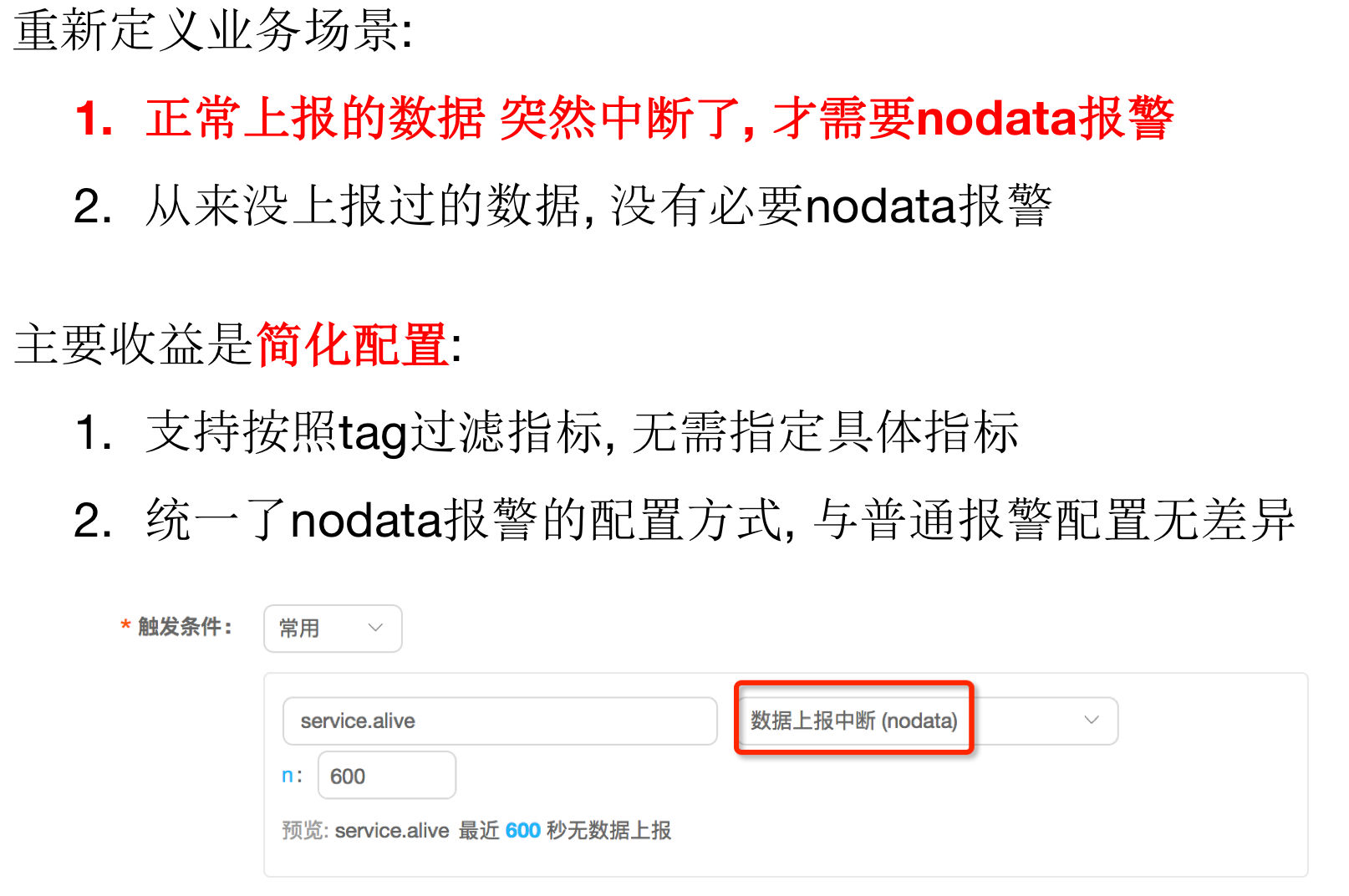
nodata报警比较小众,只适用于 核心指标 + 数据驱动报警的场景,有兴趣可以私聊交流下。
以上,是DD-Falcon相比OF的一些主要改进,再次概括下:
- 监控数据按服务单元分类
- 增加垃圾数据清洗
- 分级索引
- 精简RRA
- 巡检大盘支持同环比
- 重组看图首页
- 报警数据获取由推变拉
- 干掉报警模板
- 重新定义nodata
已知问题
DD-Falcon目前 主要面临如下问题,
- 非周期的数据 处理能力不足
- 报警延时风险
- 断点, 环比看图不易发现问题
- 历史数据严重有损(rrdtool不能很好地支持非周期数据)
- 打通非时间序列化的系统
- trace(目前通过 服务、机器、指标、时间段这四个固定维度,做关联跳转)
将来规划
DD-Falcon的平台建设工作,已经趋于完善。后续,我们计划在如下几个方面重点投入:
- 全快准稳的发现问题
- 智能报警(低成本)
- 集群报警
- 辅助定位问题
- 基于服务间 关联关系的报警
- 个性化的看图解决方案(Grafana)
社区介绍
欢迎大家,加入Open-Falcon的开源社区:
- 官网: http://open-falcon.org
- Github: https://github.com/open-falcon
- QQ讨论组: 373249123 / 516088946 / 469342415
- 微信公众号: OpenFalcon

本文对应的演讲PPT,参见 这里