导读
本文记录了一些有意思的理论哲学、方法、规律、原则,以及少量的个人感悟扩展,期寄对运维体系建设有所帮助。
理论哲学
哥德尔不完备定理:一个系统一定存在自身无法解释的问题,即哥德尔不完备性定理。原文是,在一些形式化的数学系统中、必定存在一些陈述无法在该系统内被证明。
维克的理论之钟:理论的普适性、准确性、简单性,三者不可兼得(类似分布式CAP理论),又称维克的理论之钟。
思维方法
归纳法:从特殊情况出发,通过总结共性和规律、得出一般性结论。归纳法是一种基于经验和观察的、自下而上的思维方式(Bottom Up)。归纳法能帮我们发现新规律、新结论,但它并不能保证结论的正确性,因此在归纳法实践中要加强结果的检验和验证。
演绎法:从一般原则或前提出发,通过严格的推理、得出特殊情况下的结论。演绎法是一种基于逻辑推理的、自上而下的思维方式(Top Down)。演绎法必须建立在正确的前提、正确的逻辑推理之上,否则得到的结论是不可靠的,在很多情况下演绎法得到的结论并不完备。
第一性原理:又称基本原理、基本定理。自然科学解释是,从最基本的物理、化学原理出发,推导出更复杂的规律和结论。商业视角解释是,从事物最基本的原理出发,拆分要素&解构分析、找到实现目标的最优路径(First Principles)。第一性原理不同于归纳法、演绎法,它不依赖任何经验&实验(归纳)、假设&模型(演绎)。使用第一性原理时,出发点要准确、分析过程要严密、不能陷入比较思维。
发展规律
康威定律:组织结构决定产品形态。Conway’s Law,想要什么样的系统、就搭建什么样的团队,有什么样的团队、就尝试搭建什么样的系统。
墨菲定律:多次重复后,小概率事件必然发生。Murphy’s Law。
海恩法则:每1次严重事故的背后,必然有29次轻微事故、300次未遂事故、1000个事故隐患。Hain’s Law。
灰犀牛:显而易见(大概率)、但常常被忽视的风险,是一个金融术语。相对应的,黑天鹅比喻 小概率但影响巨大的、偶发事件。
李嘉图定律:资产定价的比较优势被指数级放大,价值以指数级增速、向优质资源靠拢。垄断效应。
J曲线:滞后效应,指的是一国货币贬值时,该国贸易收支及经常帐户收支状况一般并不能立即改善,往往要滞后一段时间。
技术成熟度曲线:Gartner技术成熟度曲线(Gartner’s Hype Cycles),以图形方式展示了技术和应用的成熟度和采用情况,以及它们与解决实际业务问题和利用新机会的潜在相关性。
纳什均衡:Nash Equilibrium,在策略博弈中形成了这样一种策略组合,即每个参与人的策略都是最优选择、更换策略不会带来更多收益,这个博弈结果就是纳什均衡。纳什证明,在有限策略的前提下,纳什均衡一定存在。
管理理论
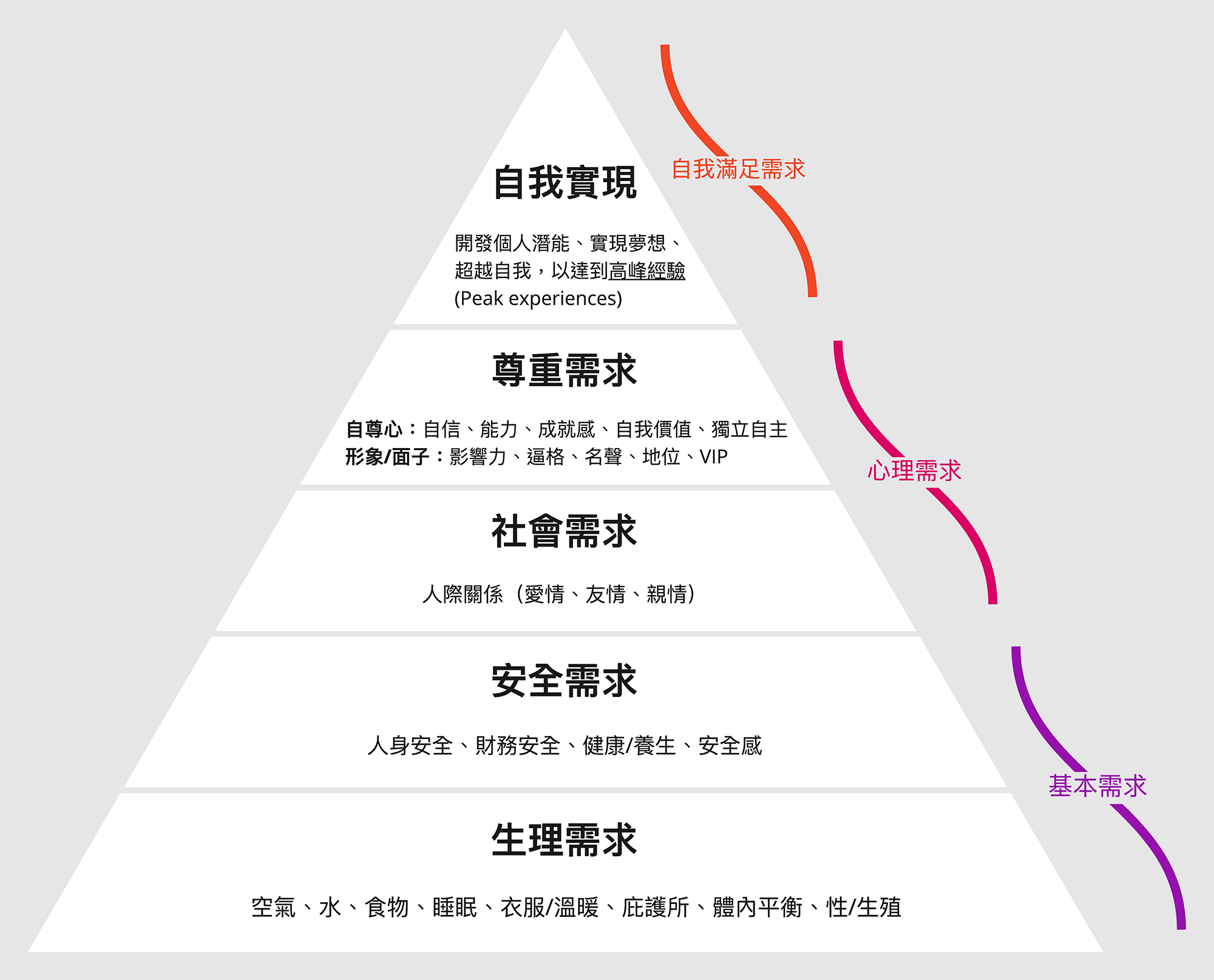
马斯洛需求层次:心理学中的激励理论。马斯洛需求层次分为五级结构,自底向上依次是:生理(食物和衣服)、安全(工作保障)、社交(社会友谊)、尊重、自我实现。
体系框架
奥克姆剃刀:如非必要、勿增实体。
阿姆达尔法:从系统的角度出发、设计优化方案,优先做ROI最高的部分。体现了系统思维。
波特五力:企业竞争的战略分析模型,五个维度分别是上游、下游、竞对、跨行替代者、自身。五力具体是供应商的议价能力、购买者的议价能力、潜在竞争者进入的能力、替代品的替代能力、行业内竞争者现在的竞争能力。
技术框架
云服务模型:SaaS(软件即服务),PaaS(平台即服务),IaaS(基础架构即服务)。
微服务架构:又称微服务,是一种软件架构、组织方式。
DevOps:是一组过程、方法与系统的统称,用于促进开发、技术运营和质量保障(QA)部门之间的沟通、协作与整合。它的目标是缩短从开发到部署的周期,通过打破开发、测试、运维之间的壁垒,实现持续交付(Continuous Delivery)。
GitOps:将技术对象的代码、配置、环境等通过Git进行管理,实现「版本控制、流程自动化」如代码合并触发CICD,效果上做到 可审计、可重复(相似说法是幂等 最终一致)。可重复的一个好的实践是声明式,而非命令式。
FinOps:领域内尚未形成统一认知。
以下是理论的详细解释。
微服务架构
微服务架构简称微服务,是一种软件架构、组织方式。通过微服务,可将大型应用按功能或需求、分解成多个独立的组件。每个组件都具备自主性,能独立开发、部署、运营、扩展;每个组件都具备专用性,有各自的责任领域,针对一组功能、专注于特定问题;组件之间采用网络通信,对外提供完整的功能。微服务架构通常是相对于整体式架构而言的,它的显著特点包括:责任清晰、小服务(SOA)、独立进程、独立部署、轻量级通信、分布式管理。
微服务之父马丁.福勒,对微服务大概的概述如下:
就目前而言,对于微服务业界并没有一个统一的、标准的定义。但通在其常而言,微服务架构是一种架构模式或者说是一种架构风格,它提倡将单一应用程序划分成一组小的服务,每个服务运行独立的自己的进程中,服务之间互相协调、互相配合,为用户提供最终价值。服务之间采用轻量级的通信机制互相沟通(通常是基于 HTTP 的 RESTful API ) 。每个服务都围绕着具体业务进行构建,并且能够被独立地部署到生产环境、类生产环境等。另外,应尽量避免统一的、集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构建,可以有一个非常轻量级的集中式管理来协调这些服务。可以使用不同的语言来编写服务,也可以使用不同的数据存储。
微服务架构有明显的优势、劣势,包括:
- 低耦合:生命周期彼此独立。微服务促进了2-5人的小型独立团队,开发、迭代效率更高;微服务间通过网络通信,能够独立部署、运营、功能集成&扩展,解除了语言限制
- 高内聚:服务功能模块化。代码易理解,聚焦在特定的业务功能,形成内聚;代码可复用,避免了重复造轮子
- 更复杂:模块数量级增加,链路复杂度指数级上升,给架构、运维、安全带来更多的分布式挑战;复杂性从代码转移到了设计、运营
微服务架构常见的设计模式,包括:
- 独享数据库,Database per Microservice,为每个微服务提供自己的数据存储,服务之间在数据库层不存在强耦合
- 事件源,Event Sourcing,所有更改将被保存为一系列不可变的事件,事件总线、事件驱动
- 命令和查询职责分离,CQRS,系统的数据读、写指令分离,强化单一职责原则和分离关注点
- Saga分布式事务,有点像分布式一致算法中的本地生效策略,用来解决分布式一致性和生效效率问题
- 面向前端的后端,BFF,背景是,移动端和Web端有不同的屏幕尺寸、显示屏、性能、能耗和网络带宽,同一功能对API的需求不同。我方称为UI Server
- API网关,类似Ingress、InRouter。背景是,客户端可能需要连接非常多的微服务,这将变得繁杂和具有挑战性
- Strangler,通过API网关,将单体服务流量、逐步的迁移到微服务。这是微服务逐步改造、逐步切流的方案。我方通过Router逐步切流到Ingress,是该模式的实践
- 断路器,一个微服务通过代理请求另一个微服务,其工作原理类似于电气断路器,代理通过统计最近发生的故障数量,并使用它来决定是继续请求还是简单的直接返回异常
- 外部化配置,即代码、配置分离
- 消费端驱动的契约测试,消费端制定测试套件、微服务端将测试套件添加到自动化测试中。我方接口自动化测试,是该模式的实践
DevOps
DevOps这个词来源于2009年在比利时根特市举办的首届DevOpsDays大会,为了在Twitter上更方便的传播,由DevOpsDays缩写为DevOps。
DevOps是一组过程、方法与系统的统称,用于促进开发、技术运营和质量保障(QA)部门之间的沟通、协作与整合。它的目标是缩短从开发到部署的周期,通过打破开发、测试、运维之间的壁垒,实现持续交付(Continuous Delivery)。
DevOps落地依赖组织文化(Culture)、自动化(Automation),同时也要关注结果度量(Measurement)、知识分享(Sharing),所谓的CAMS四原则。CICD等自动化技术只是其中一个环节,并非全部。
效果方面,相比于软件开发的瀑布模式、敏捷开发,DevOps将开发、测试、部署三个环节打通,做到了快速迭代、持续反馈;其价值,不再限于开发阶段、而是贯穿了软件全生命周期。
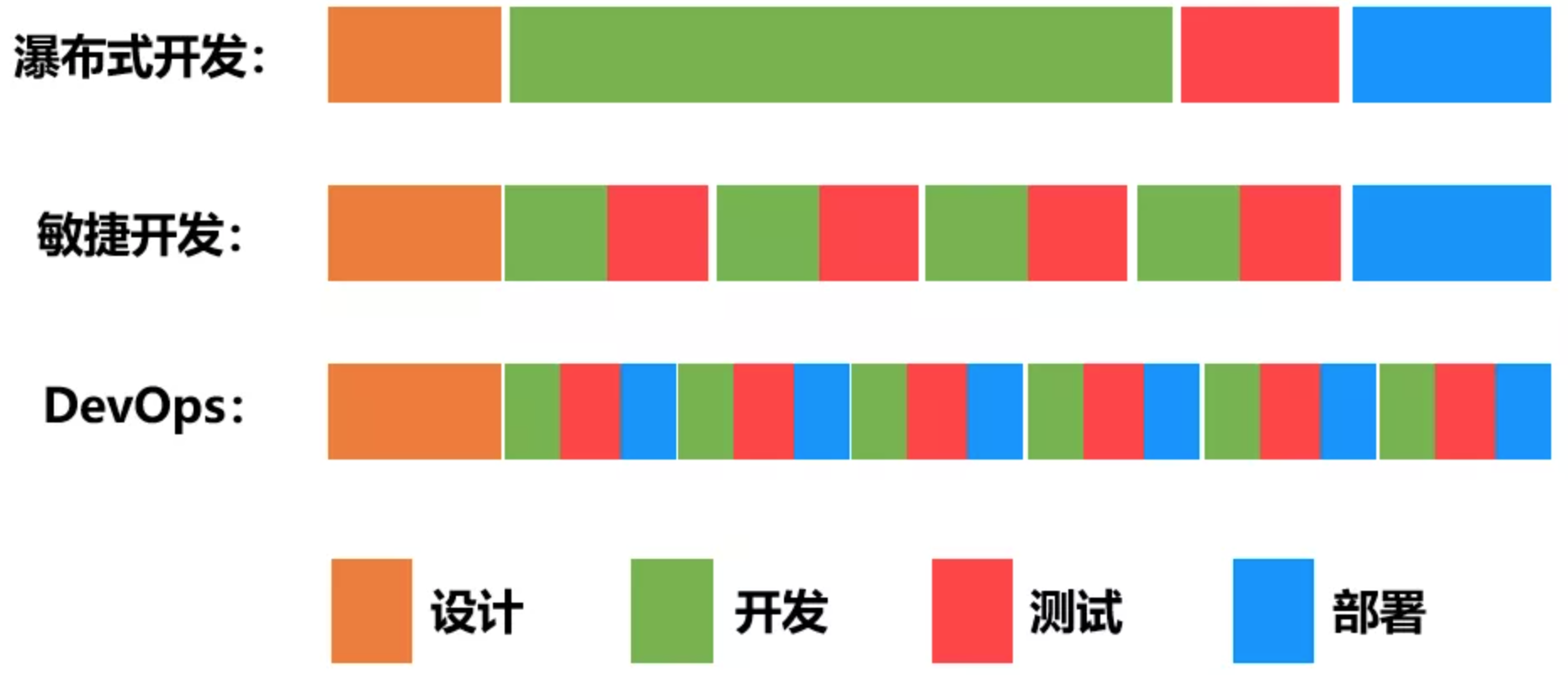
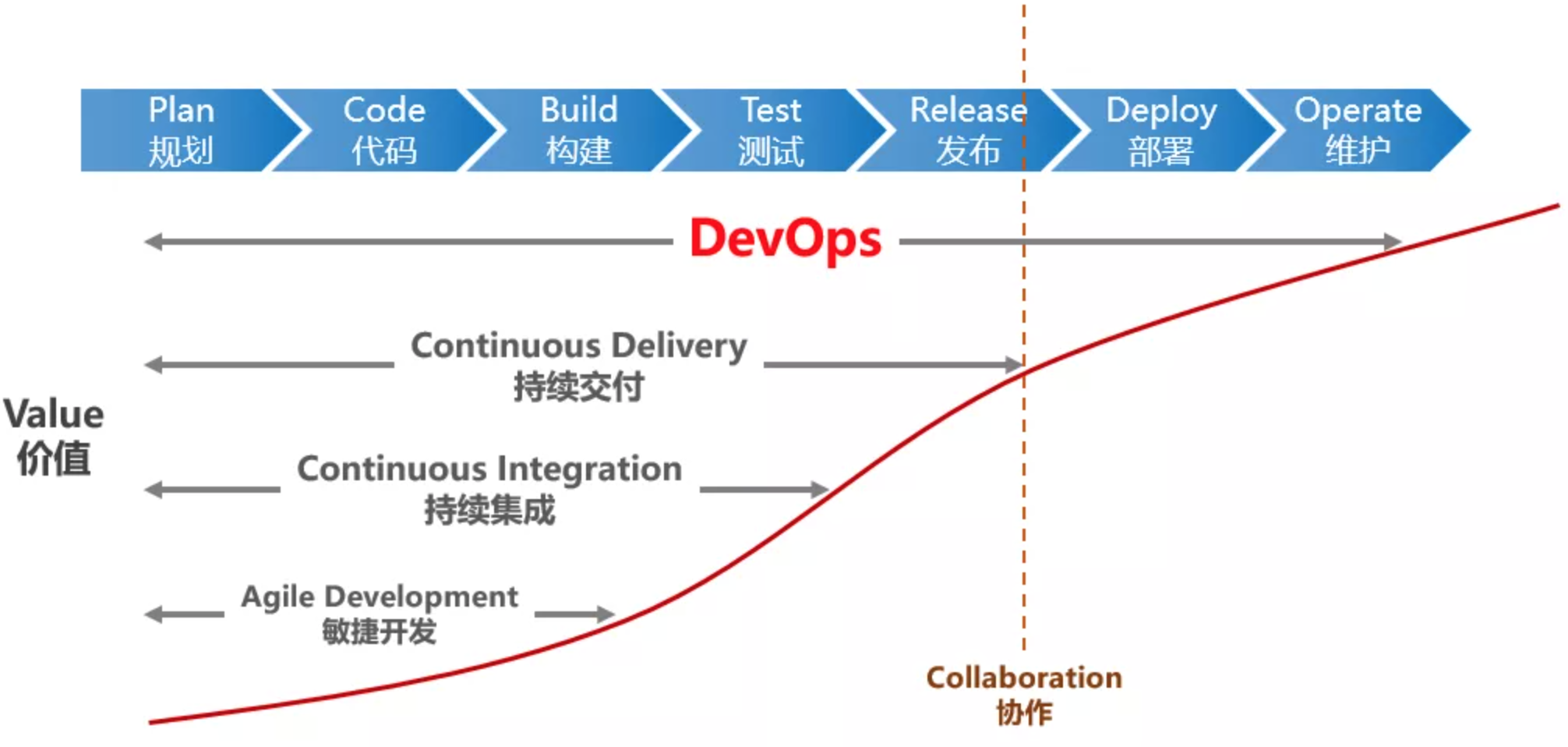
当前盛行的云原生概念,吸纳和演进了DevOps理念,云原生技术促进了DevOps的结果达成。
本文主要内容,引用自鲜枣课堂的《DevOps到底是什么意思》。
GitOps
GitOps最早由Weaveworks公司在2017年提出,是IaC在K8S生态下的一种实现,也是对DevOps理念的一次实践落地。GitOps具备声明式基础设施、版本化、流程自动化等特征,做到了配置变更可审计、可重复、一致性,完全符合IaC定义。同时GitOps又超出了常规的IaC能力,因为它使用Git做代码管理,并最大限度的复用了Git的工具生态。一个典型的GitOps实现如下图,
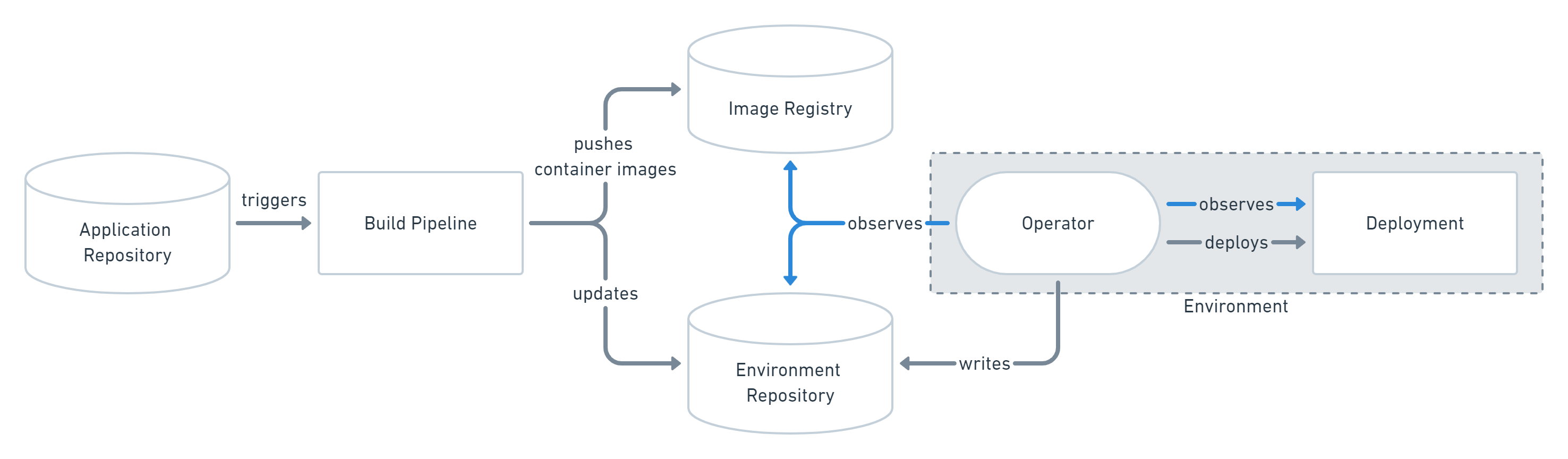
GitOps将应用的所有环境配置都通过Git进行管理,并通过自动化的流程进行交付和变更,这样就是GitOps的核心理念。具体的,
GitOps代码分为应用仓库、环境仓库两部分。应用仓库保存应用源码、应用部署描述等信息,对应上图中的Image Registry。环境仓库则描述了某部署环境(如生产环境、测试环境)的构成,包括应用列表、基础服务列表、对应的配置和版本等,对应上图中的Environment Repository。
GitOps操作定义了一个完全自动化的控制器Operator,该控制器负责观察、对比真实部署环境的状态(基线是环境仓库的描述),并确保两者达成一致。
参考文献:GitOps
FinOps
FinOps基金会(F2)成立于2019年02月,于2022年06月并入Linux基金会(LF)。F2起源于Cloudability的客户顾问委员会会议(Cloudability’s quarterly Customer Advisory Board meeting),在这个会上众多从业者呼吁成立一个独立于云厂商的社区、一起讨论云成本的最佳实践。Cloudability一家云服务成本管理平台。当前,F2的技术咨询委员会阵容并不是太强大。
云服务模型
通常有三种云服务模型:SaaS(软件即服务),PaaS(平台即服务)和IaaS(基础架构即服务)。
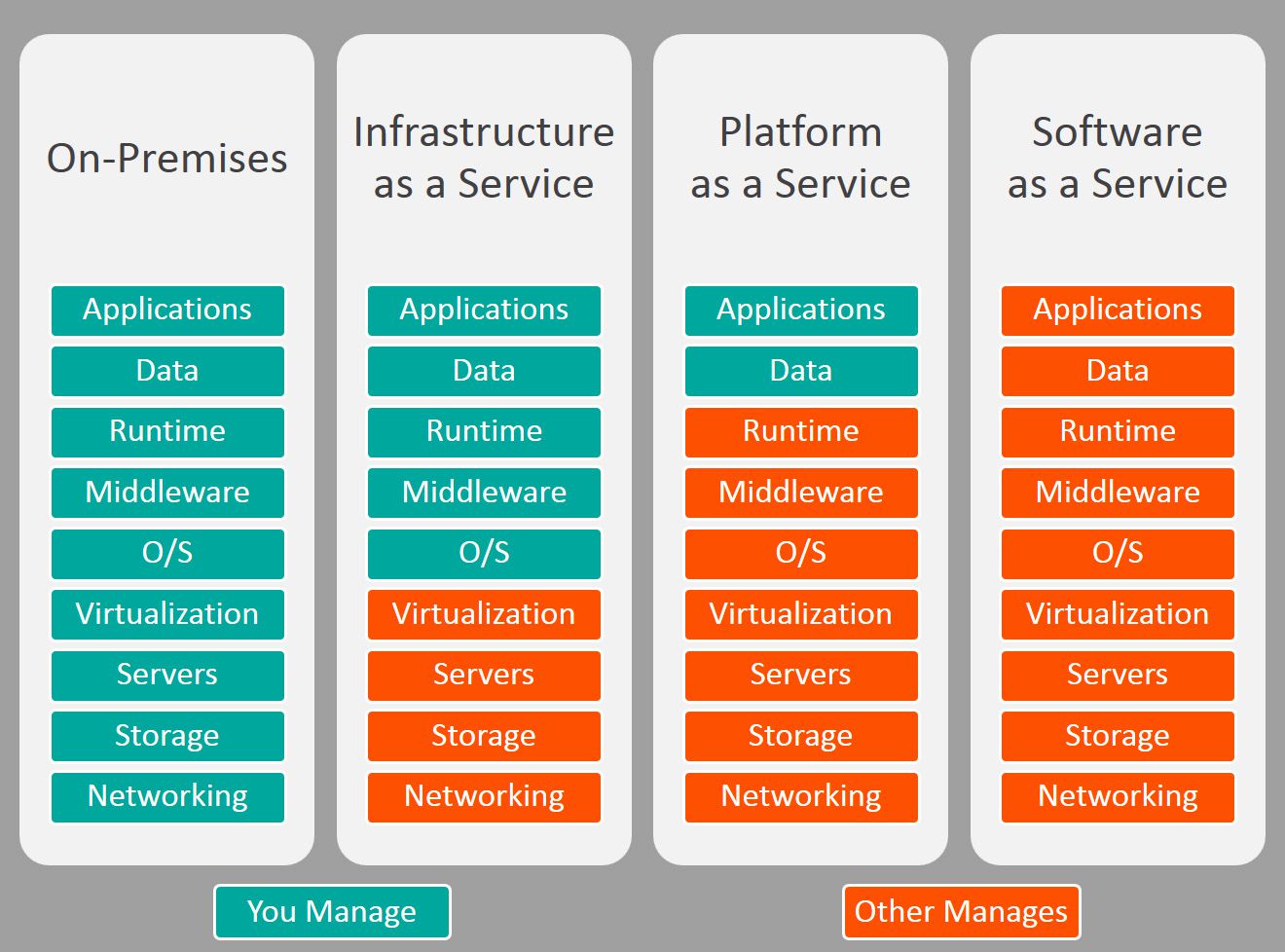
SaaS代表了云市场中企业最常用的选项。SaaS利用互联网向其用户提供应用程序,这些应用程序由第三方供应商管理。大多数SaaS应用程序直接通过Web浏览器运行,不需要在客户端进行任何下载或安装。由于其网络传输模式,SaaS无需在每台计算机上下载和安装应用程序,而在每台计算机上下载和安装应用程序正是IT员工的噩梦。通过SaaS,供应商可以管理所有潜在的技术问题,例如数据、中间件,服务器和存储,因此企业可以简化其维护和支持。典型的SaaS包括Google Apps、Dropbox、Salesforce、Cisco WebEx、Concur和GoToMeeting等。
PaaS为某些软件提供云组件,这些组件主要用于应用程序。PaaS为开发人员提供了一个框架,使他们可以基于它创建自定义应用程序。所有服务器,存储和网络都可以由企业或第三方提供商进行管理,而开发人员可以负责应用程序的管理。PaaS的交付模式类似于SaaS,除了通过互联网提供软件,PaaS提供了一个软件创建平台。该平台通过Web提供,使开发人员可以自由地专注于创建软件,同时不必担心操作系统、软件更新,存储或基础架构。PaaS允许企业使用特殊的软件组件设计和创建内置于PaaS中的应用程序。由于具有某些云特性,这些应用程序或中间件具有可扩展性和高可用性。典型的PaaS包括AWS Elastic Beanstalk、Windows Azure、Heroku、Force.com、Google App Engine,Apache Stratos,OpenShift。
IaaS由高度可扩展和自动化的计算资源组成。IaaS是完全自助服务,用于访问和监控计算、网络,存储和其他服务等内容,它允许企业按需求和需要购买资源,而不必购买全部硬件。IaaS通过虚拟化技术为组织提供云计算基础架构,包括服务器、网络,操作系统和存储等。这些云服务器通常通过仪表盘或API提供给客户端,IaaS客户端可以完全控制整个基础架构。 IaaS提供与传统数据中心相同的技术和功能,而无需对其进行物理上的维护或管理。IaaS客户端仍然可以直接访问其服务器和存储,但它们都通过云中的“虚拟数据中心”。与SaaS或PaaS相反,IaaS客户端负责管理应用程序、运行时、操作系统,中间件和数据等方面。但是,IaaS的提供商管理服务器、硬盘驱动器、网络,虚拟化和存储。一些提供商甚至在虚拟化层之外提供更多服务,例如数据库或消息队列。典型的IaaS包括DigitalOcean,Linode,Rackspace,AWS,Cisco Metapod,Microsoft Azure,Google Compute Engine(GCE)等。
本文主要内容,引用自《一张图看懂IaaS、PaaS和SaaS的区别》。
技术成熟度曲线
Gartner技术成熟度曲线(Gartner’s Hype Cycles),以图形方式展示了技术和应用的成熟度和采用情况,以及它们与解决实际业务问题和利用新机会的潜在相关性,Gartner原文。
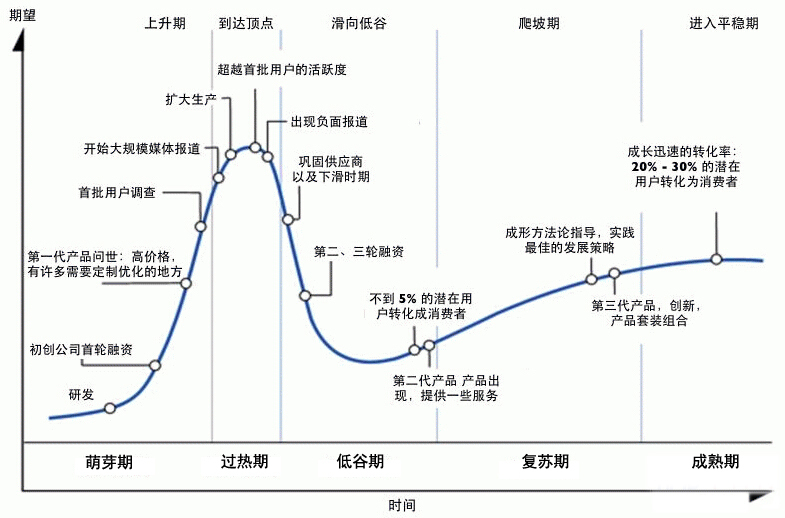
每个技术成熟度曲线,都将新技术的生命周期划分为如下五个关键阶段,
- 技术萌芽期:潜在的技术突破即将开始。早期的概念验证报道和媒体关注引发广泛宣传,通常不存在可用的产品、商业可行性未得到证明
- 期望膨胀期:早期宣传产生了许多成功案例,通常也伴随着多次失败。某些公司会采取行动,但大多数不会
- 泡沫破裂谷底期:随着实验和实施失败,人们的兴趣逐渐减弱,技术创造者被抛弃或失败。只有幸存的提供商改进产品,使早期采用者满意,投资才会继续
- 稳步爬升复苏期:有关该技术如何使企业受益的更多实例开始具体化,并获得更广泛的认识。技术提供商推出第二代和第三代产品,更多企业投资试验,保守的公司依然很谨慎
- 生产成熟期:主流采用开始激增。评估提供商生存能力的标准更加明确,该技术的广泛市场适用性和相关性明显得到回报
技术成熟度曲线在运维领域同样适用,如辅助判断云原生的成长阶段、决定运维大规模投入的时机。
康威定律
康威定律(Conway’s Law): 「组织结构决定产品形态」,想要什么样的系统、就搭建什么样的团队,有什么样的团队、就尝试搭建什么样的系统。
康威定律,是马尔文-康威1967年提出的,起初发表在杂志上,后经《人月神话》引用而出名、并被命名为康威定律。康威定律包括四个定律,
- 第一定律: 组织沟通方式决定系统设计
- 原文: Communication dictates design
- 举例: 想要搞微服务,公司的团队就要按照微服务来划分。想要什么样的系统,就搭建什么样的团队;有什么样的团队,就尝试搭建什么样的系统、不要无畏挣扎,如小公司团队没得划分、搞微服务就是找死
- 第二定律: 时间再多一件事情也不可能做的完美,但总有时间把他做完
- 原文: There is never enough time to do something right, but there is always enough time to do it over
- 举例: 人手永远是不够用的,事情也永远做不完,但可以一件一件的来。这也是Devops要解决的问题,即持续的开发、测试、交付、部署,过程中不断反馈调整
- 第三定律: 线型系统和线型组织架构间有潜在的异质同态特性,这是第一定律的具体应用
- 原文: There is a homomorphism from the linear graph of a system to the linear graph of its design organization
- 第四定律: 大组织比小系统更倾向于分解
- 原文: The structures of large systems tend to disintegrate during development, qualitatively more so than with small systems
- 举例: 组织沟通成本随着人员数量指数增长,沟通成本=Nx(N-1)/2,这也是为什么互联网公司往往追求小团队
从康威定律可以看出,技术架构绝不仅仅是一个技术问题,更是公司组织和政治问题、公司越大越是如此。参考了原文。
墨菲定律
墨菲定律:「多次重复后,小概率事件必然发生」。原文是:如果坏事情有可能发生,那么它一定会发生,只要事情的重复次数足够多。墨菲定律,由美国空军上尉工程师爱德华·墨菲(Edward A. Murphy)1949年提出。
数学依据:假设某事件在一次实验(活动)中发生的概率为p(p>0),则在n次实验(活动)中至少有一次发生的概率为P=1-(1-p)n。由此可见,当实验次数n趋向于无穷时、P会越来越趋于1,即成为必然事件。
结合运维领域,不要轻易漏掉小概率隐患,不要相信小概率事件、该发生的一定会发生。
海恩法则
海恩法则:「每1次严重事故的背后,必然有29次轻微事故、300次未遂事故、1000个事故隐患」。海恩法则(Hain’s Law),是德国飞机涡轮机的发明者帕布斯·海恩提出的、航空飞行安全法则。
海恩法则强调,任何事故都是可以预防的。关键点,一是量变引起质变、严重事故是隐患累积的结果;二是再好的技术、再完美的规章,在实际操作层面也无法取代人自身的素质和责任心。
结合运维领域,故障前要重视隐患、不要让它变成事故,故障后要认真复盘发掘隐患、避免再次入坑。
灰犀牛
灰犀牛是一个金融术语,比喻「显而易见(大概率)、但常常被忽视的风险」;相对应的,黑天鹅比喻「小概率但影响巨大的、偶发事件」。灰犀牛理论来源:非洲草原上的灰犀牛,体形庞大、行动迟缓,远远看着似乎并没有威胁;而当它一旦被触怒、向你奔袭而来时,能够逃脱的几率微乎其微。
黑天鹅其实是一种偶发性、不可预见的,之所以叫黑天鹅,就是因为它突然出现,无法预防。灰犀牛事件不是随机突发的事件,而是在出现一系列警示信号和危险迹象之后,如果不加处置就会出现的大概率事件。从量变引起质变的角度看,灰犀牛理论跟海恩法则有些类似。
阿姆达尔法则
阿姆达尔法:「从整体的角度设计优化方案,优先做ROI最高的部分」,系统思维。一个整体包含了很多部分,先优化哪个部分、后优化哪个就有讲究了,阿姆达尔法则是帮助大家挑出当前最需要优化的那个部分。其数学描述,大体如下:

上述图片,引用自:知乎专栏
Gene Amdahl进行了一个富有洞察力的观察:提升系统的一个部分的性能对整个系统有多大影响。这一观察被称为Amdahl’s Law(阿姆达尔定律)。
李嘉图定律
李嘉图定律:社会生产力发展和社会进步,是以牺牲某些阶层的利益为代价的。在信息时代,李嘉图定律的新含义是:「资产定价的比较优势被指数级放大,价值以指数级增速、向优质资源靠拢」。
在信息化时代,”李嘉图定律”被赋予了新的含义:资产定价的比较优势被指数级放大,价值以指数级增速、向优质资源靠拢。借用吴军的对硅谷地价的解释:一个地区中心和周边的经济关系。中心地价高,可以辐射到周边;经济好的时候,中心会带动周边一起涨;经济不好的时候,周边会暴跌,但中心地区因为总有人想挤进去,因此能够基本上维持住。
借用网络资源也是吴军观点,解释如下:
李嘉图是19世纪英国经济学家。书中讲到的李嘉图定律其实是地租定律:土地租金是土地使用者支付的价格,它是有垄断性(稀缺性)决定的,而不是由地主在上面做的投资和改良的成本决定的;它的价格受限于租用者(农民)能够承担的价格。 土地本是天赐物,根据劳动价值论,土地是没有地租可收的。但是土地有好(产量高)和不好(产量低)之分。人们都想要好的土地,因此就会有人愿意付出溢价以获得那些好土地的使用权,即支付地租。越是好的土地(无论是产量高还是地理位置好)就越稀少,租金就越贵。这样,从租金最高的土地,到免费、贫瘠的荒地,就形成了一级级价格的落差。
到了信息时代,李嘉图定律被赋予了更新更广的含义,即对能够比较出优势的资产和经济要素进行定价。并且落差较之农耕时代和工业时代更大,甚至是指数级的。 比如同样是高中老师,张老师比李老师辅导的学生高考成绩更好,那么张老师就如同值钱的土地,他的劳动会获得比同行更高的溢价。在信息时代,信息越来越透明,流动性越来越快,传播越来越远,张老师的名气越来越大,报他名下的学生越来越多,张老师的劳动价格就会越抬越高;李老师的生源和价格很可能会越来越难保障。比如小时候我们在农村看电影,都是露天放映,一到放电影的日子,大家伙都是早早吃了晚饭,搬个板凳,去占地儿等着,人太多看不到,前面的坐着,后面的站着,再后面的站凳子上,站旁边建筑物上,小朋友骑大人脖子上,各种挪呀、挤呀,场面很是壮观;现在,露天放电影估计只能在某些古文化景区里看到了。比如小时候我们都是在村子里就近上学,老师都是村子里的有些文化知识的民办教师;去年回去,发现村上的小学大门紧锁,隔着门缝看进去,杂草丛生,现在的孩子从幼儿园开始就送到镇上或者县城去读书了。
J曲线(滞后效应)
J曲线是一个经济学领域术语,定义是:一国货币贬值时,该国贸易收支及经常帐户收支状况一般并不能立即改善,往往要滞后一段时间(滞后效应)。由于这种经常帐户收支变动的轨迹成英文字母J的形状,所以被称为J曲线。如下图,
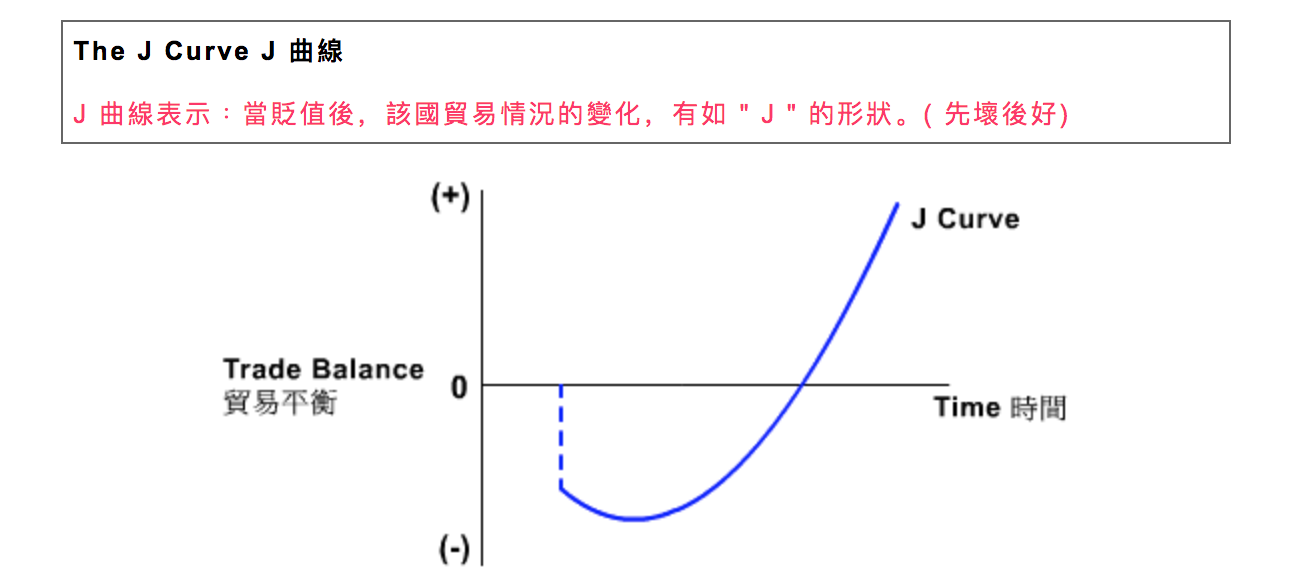
举例1. 中国改革开放、实行市场经济之初遇到了这种情况。物价上涨、老百姓开始抱怨;之后,在走过最低点后,经济越来越活、发展得很好,进入了J曲线的上升期。与中国比,俄罗斯则是反例。俄罗斯一开始找到了改革方向,但之后一直在摇摆,每做一件事都似乎是在解决当下最紧迫的问题,虽然在普京担任总统的前几年经济增长看似不错,但在一个较长的时间上看起来其实是在兜圈子、白白浪费了机遇。
举例2. 不仅国家的发展会遇到J曲线,我们个人学习知识和技能也会如此。比如认真从事网球或者高尔夫球这一类球类运动,你会有这样的体会:一开始你可能有一个不好的动作,好的教练会想办法纠正你,但是在随后一段时间,你反而变得不会打球了,成绩下降。不过过几个月之后,你的动作变得标准了,球技就有了大幅度的提高。
启示:了解了J曲线,了解了滞后效应,我们做事情就需要有点耐心,如果我们相信一个新的方法是好的,就坚持一段时间再下结论,不要根据实时的反应草率给出结论。
奥克姆剃刀
奥克姆剃刀原则:「如非必要、勿增实体」。
这句话是由英国数学家、哲学家威廉·奥卡姆(William of Ockham)提出的,他生活于14世纪初。
第一性原理
第一性原理(First Principle),指的是:回归事物最基本的条件,将其拆分成要素、解构分析,从而找到实现目标的最优路径。第一性原理不同于归纳法、演绎法,它不依赖任何假设和模型、且实验无关,例如在物理学中,牛顿定律和能量守恒定律就是典型的第一性原理;在化学中,元素周期表和化学键理论是第一性原理。
使用第一性原理,需要关注三点。第一,找准出发点,以最本质最基础的东西作为出发点;第二,推演过程要逻辑缜密,尽量少引入估计;第三,避免比较思维,不横向对比、不随意参照同类方案或现有经验,尊重客观推演结果。
第一性原理被炒的很火,主要得益于埃隆·马斯克。他曾在采访中提到自己特别推崇”第一性原理”:”通过第一性原理,我把事情升华到最根本的真理,然后从最核心处开始推理”。运用第一性原理、而不是比较思维是非常重要的。我们在生活中总是倾向于比较,对别人已经做过的事情我们也都去做,这样只能产生细小的迭代发展。第一性原理则先回归本质、再从本质一层层往上分解”。以特斯拉汽车为例。十几年前,传统锂电池价格长期居高不下,这很大程度影响了特斯拉电动车的大众化之路。于是,创始人马斯克回归到电池组的基本要素,思考电池组是由哪些材料组成的、这些原料的市场价格是多少。结果他发现,如果从伦敦金属交易所购买电池组所需的碳、镍、铝等原材料,再由特斯拉自己建厂研发制造,而不是直接购买供应链产品,电池价格可以下降30%。
第一性原理出自自然科学,也称为基本原理、基本法则。它强调,从最基本的物理、化学原理出发,推导出更复杂的规律和结论,而不是通过归纳或演绎得到结论。
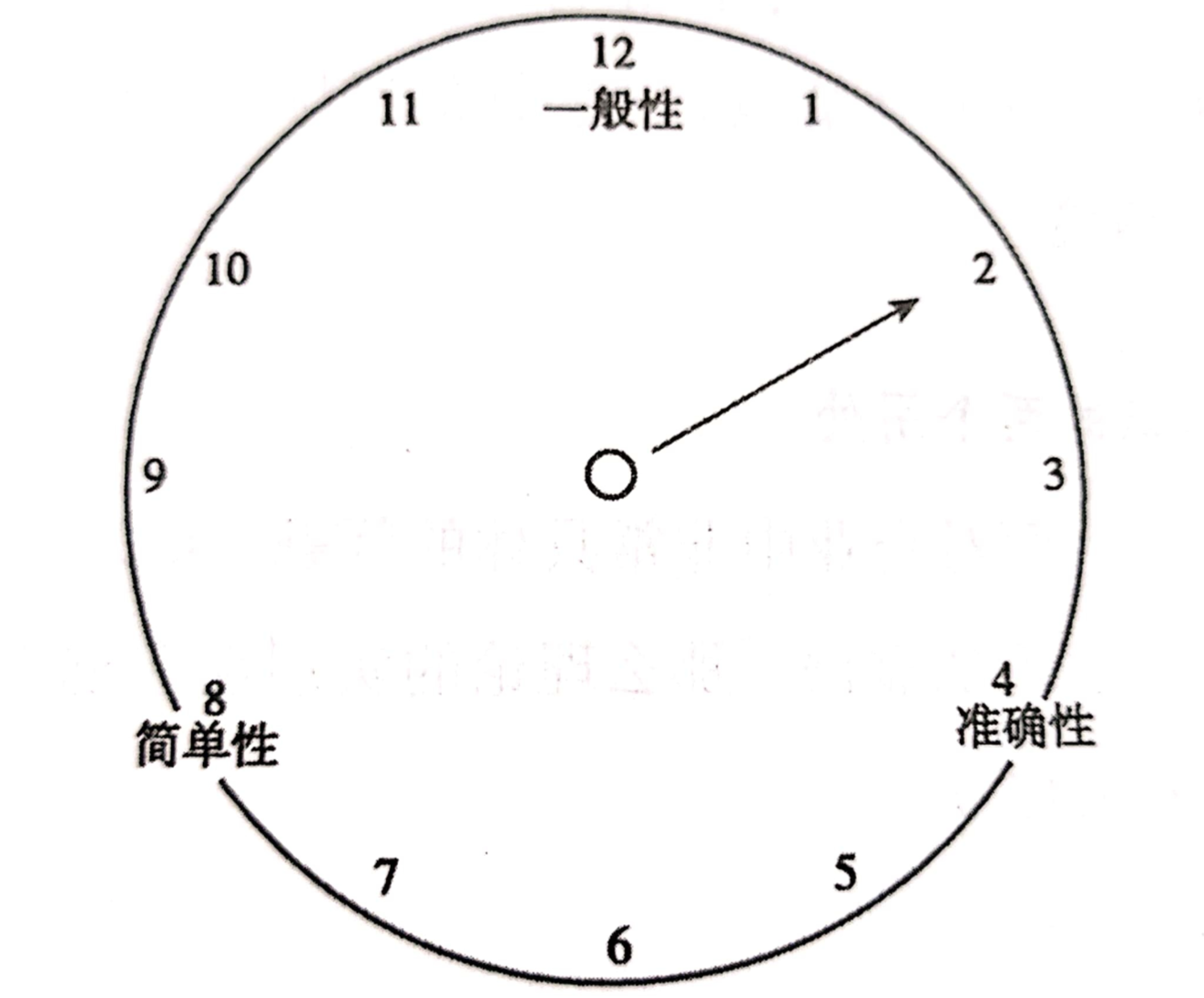
维克的理论之钟
著名管理学家卡尔·维克,提出过一个”理论之钟”模型、用于评判理论标准。理论之钟指的是:理论的一般性(普适性)、准确性、简单性,三者不可兼得(类似分布式CAP理论)。
哥德尔定理(不完备性)
哥德尔定理指的是:一个系统一定存在自身无法解释的问题,又称为哥德尔不完备性定理。
哥德尔定理是由奥地利数学家库尔特·哥德尔于1931年提出的重要数学定理,核心思想是关于形式系统的自指性和不完备性。哥德尔定理的第一部分,被称为哥德尔不完备性定理,表明在任何包含基本算术的形式系统中,总存在一个陈述,它既不能被证明为真,也不能被证明为假。换句话说,这个形式系统是不完备的,无法证明所有的真陈述。哥德尔定理的第二部分,被称为哥德尔第二不完备性定理,表明在包含基本算术的形式系统中,系统的一致性无法在系统内部被证明。也就是说,如果一个形式系统是一致的,那么它无法在自身内部被证明为一致。
哥德尔定理的重要性在于它揭示了数学和逻辑的局限性,即:无论我们使用多么强大的形式系统,总会存在一些陈述无法被证明,或者系统的一致性无法在系统内部被证明。
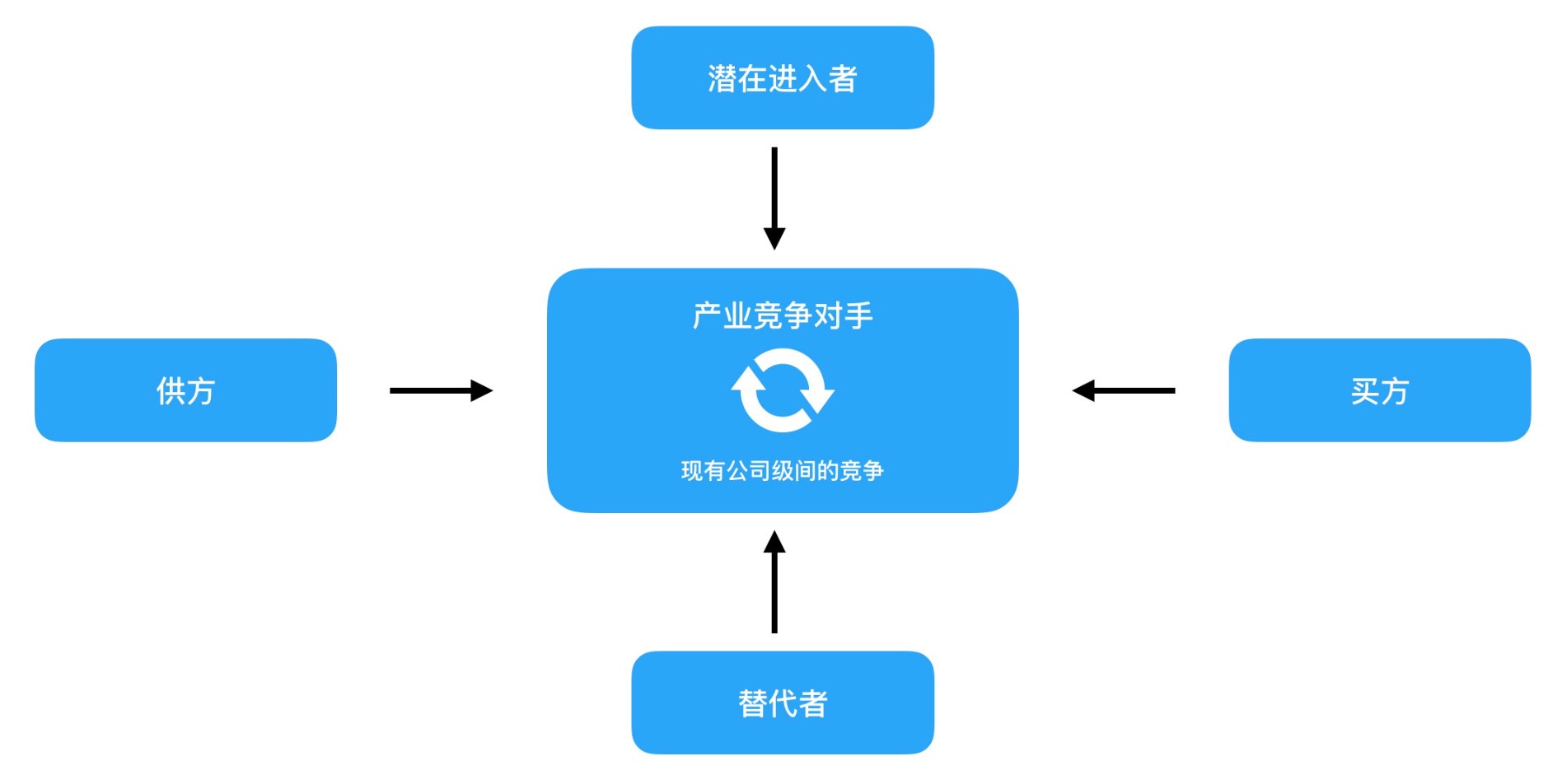
波特五力模型
波特五力分析模型是迈克尔·波特(Michael Porter)于80年代初提出,主要用于企业竞争战略分析。五力分别是:供应商的议价能力、购买者的议价能力、潜在竞争者进入的能力、替代品的替代能力、行业内竞争者现在的竞争能力。五种力量的不同组合变化最终影响行业利润潜力变化。
纳什均衡
Nash Equilibrium,在策略博弈中形成了这样一种策略组合,即每个参与人的策略都是最优选择、更换策略不会带来更多收益,这个博弈结果就是纳什均衡。纳什证明,在有限策略的前提下,纳什均衡一定存在。

埃洛等级分
埃洛等级分系统Elo Rating System,又称埃洛排名系统,是一种衡量对弈活动水平的评价方法。由匈牙利裔美国物理学家阿帕德·埃洛创建。

马斯洛需求层次
马斯洛需求层次分为五级结构,自底向上依次是:生理(食物和衣服)、安全(工作保障)、社交(社会友谊)、尊重、自我实现。马斯洛需求层次是心理学中的激励理论。