导读
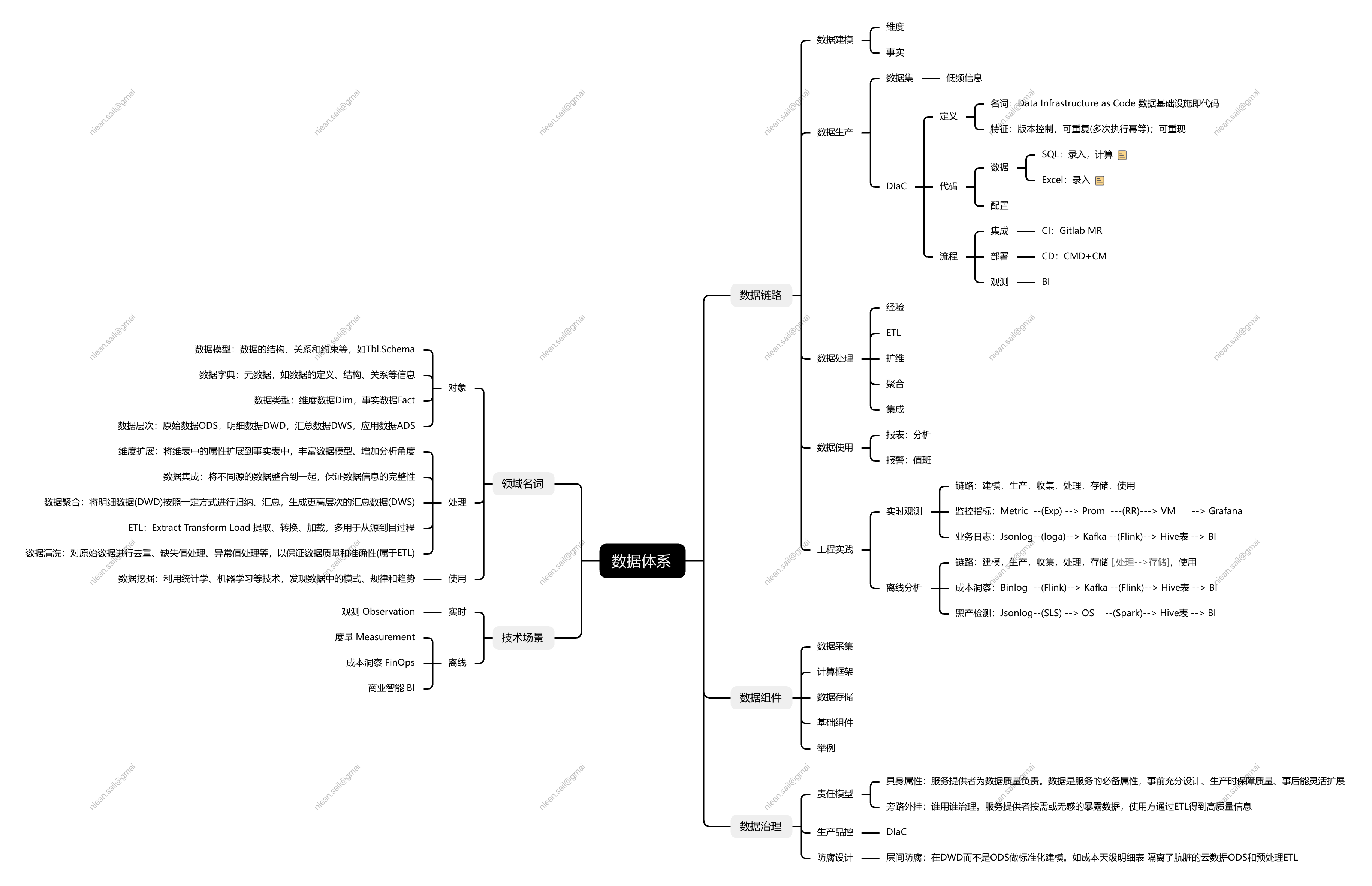
本文主要介绍基础设施领域的数据分析体系。数据体系全貌如下,
要点简述
- 数据基建:DIaC,Data Infra as Code数据基建即代码。这是我发明的领域名词,核心理念是
以代码的方式,管理数据的生命周期
数据建模
- 版本:应用层相关的数据必须带版本,即使是被应用层间接引用的事实表;参与数据生成的维表可以不带版本,但后果是无法精确重算,可以折中选用拉链表
数据生产
- DIaC:将IaC引入到数据领域、发明DIaC概念,用代码管理数据生产、用CICD实现流程合规。DIaC,Data Infrastructure as Code,数据基础设施即代码。
数据治理
- 防腐:分层结构,在DWD层做数据防腐,解耦数据的生产和使用;数据生产的ODS/ETL,通常历史包袱较重
工程实践
- 链路:离线分析,在成本洞察、OS黑产检测上磨合成熟,开始迁移到Nat流量分析等场景,时效T+1。
数据质量
- 即时反馈:要想保证数据质量,则必须将之置于强依赖链路,做到即时反馈、强制修复。如资源运营的成本归属、服务调用的名字配置、业务分析的日活指标、商业分析的核心报表
- 广泛使用:被使用的场景越多,数据质量就越有保障。这是反馈机制的延续
- 交叉互验:不同链路生成的同维数据,彼此可以交叉互验。如组织关系和服务调用推导出的模块归属、云厂商计费和三方独立计费得到月度账单。相比人工反馈,交叉互验更有可能自动化、也就更具性价比
- 绝对权威:反复强化数据质量、增加用户信心指数,优先做到数据不出错,如果出错也要内部修正、严控外溢
一些思考
- 生理特征:人脑对绝对值不敏感,好的数据分析产品呈现的一定不是绝对值。好的呈现方式,有环比、对比等
- 环比:人脑容易捕捉数字的变化趋势,如环比增幅。环比依赖正确的起始值
- 对比:对比能提供归一化的分析体验,更易于大脑理解,如单位成本。对比依赖基线建模
以下为思考过程,内容待整理。
概念
- 指数:指标,如IQ值、上证指数
洞见
- 主客观性:数据是客观的,解读数据的人是主观的。数据这门科学就像中西医混合的一门医学,既要有西医的理论、分析模型以及实验,又需要有中医的望闻问切这些个人经验
- 大小之辩:大数据,数据量大但信息少,需要数据挖掘找价值;小数据,数据量小但信息多,需要详细分析利用好
- 大数据主要针对个人数据,数据量大、但信息量很小,需要用数据挖掘算法、在浩如烟海的数据里找到珍珠
- 小数据往往由企业经营行为产生,数据量小、但数据价值很大,需要了解业务规律、才能理解数据背后蕴含的知识
- 质量往往重于数量,数据分析时,不要迷信大数据、要关注高质量的小数据,大部分核心决策都是用小数据完成的
- 常见错误:数据分析的常见局限,包括数据质量局限、因果倒置、误把相关当因果、辛普森悖论(遗漏X变量)、以偏概全、观察时间不够、伪造结果等
基础知识
- 算数平均:分组和整体的分析结论可能大相径庭,这种现象称为辛普森悖论。悖论的原因是统计模型未考虑到某个关键变量,典型如算数平均。整体平均只有在正态分布或均匀分布下才有意义
- 大数定律:当随机事件发生的次数足够多时,发生的频率会趋近于预期的概率,典型如抛硬币。赌场就是用大数定律赚钱,如将中奖比例设置为49%
- 赌徒谬误:赌徒错误的认为,过去发生的结果、可以影响未来的结果,典型如开车时的红绿灯。实际上,每个独立的事件都是相互独立的,不会相互影响
- 墨菲定律:多次重复后,小概率事件必然发生。1-(1-P)^N,随着N的增加,发生概率无限趋近于1
- 随机对照:研究者将参与者随机分配到两个或多个组中,其中一个组接受干预、其他组接受安慰剂作为对照组,这就是随机对照双盲实验。典型如A/B测试
- 幸存者偏差:只关注幸存或成功的事物,而忽视未能幸存或失败的事物,从而导致错误的推断和判断。典型如二战时期飞机修复研究
- 二八法则:又名帕累托法则,是一种幂律分布,典型如互联网领域的赢者通吃、20%的人占有80%的财富
- 马太效应:优势的人或事物会因为其优势而不断受益、并获得更多的资源,而劣势的人或事物则相反、变的更困难。马太效应得名于《圣经》中的一句话:”凡有的,还要加给他,叫他有余;没有的,连他所有的,也要夺过来”(马太福音25:29)
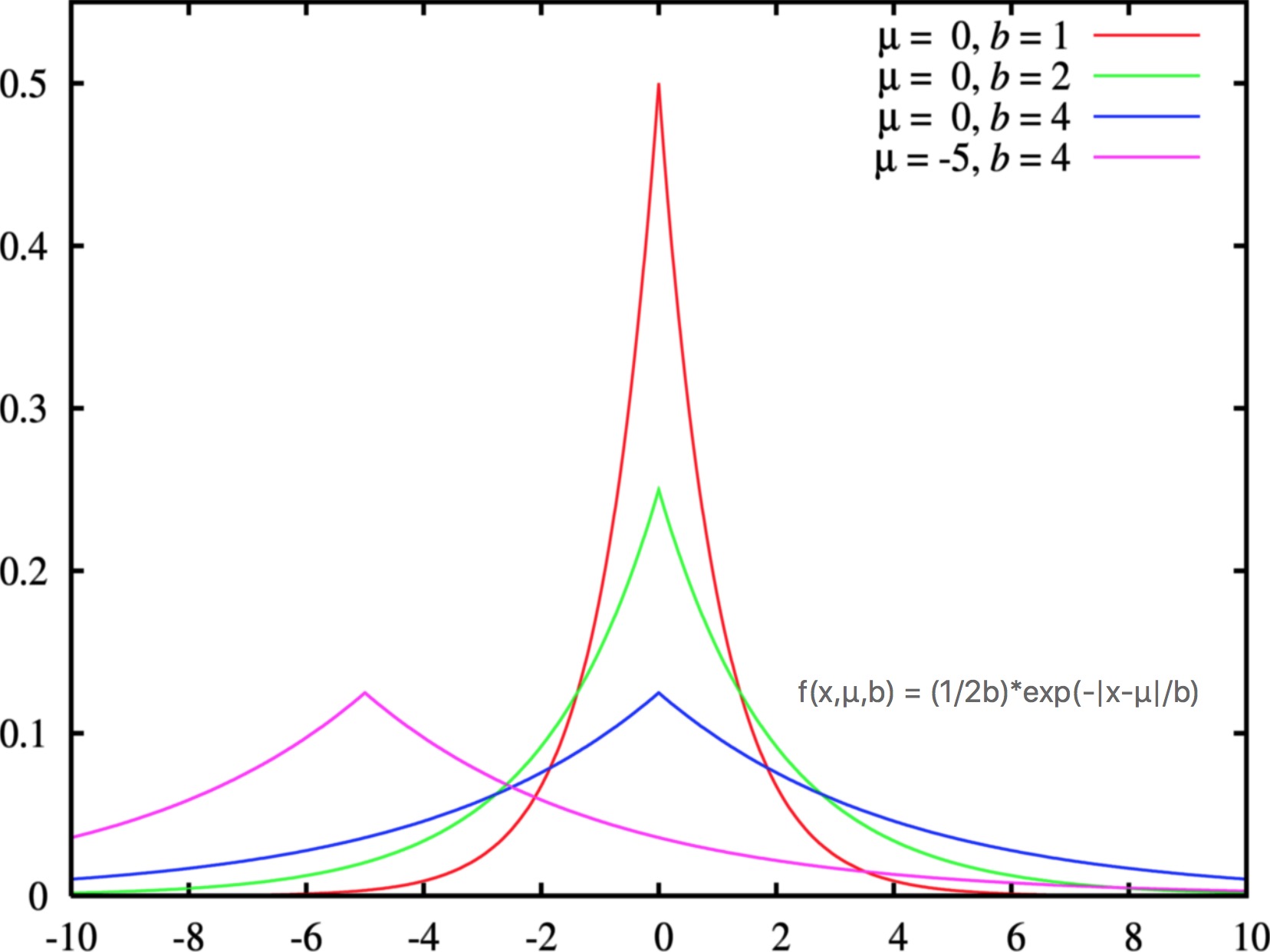
- 分布曲线:正太分布,又名高斯分布;拉普拉斯分布,又名双指数分布f(x,μ,b)=(1/2b)*exp(abs(x-μ)/b),呈现聚集效应、如房价;泊松分布
分析算法
- 精确率:Precision 精确率(准 1-误报) = TP/(TP+FP),其中TP True Postive(指马为马)、FP False Postive(指鹿为马)
- 召回率:Recall 召回率(全 1-漏报) = TP/(TP+FN),其中FN False Negative(指马为鹿)
- 置信区间:Confidence Interval 置信度、置信区间
- 聚类算法:输入杂乱无章的数据,输出若干个分门别类的小组,组内相似(内聚)、组间不同(分离)。聚类是最常见的数据挖掘算法,常见如K-Means、KNN、DBSCAN、EM方法,主要解决找中心、距离表示、收敛方法三类问题
- 分类算法:又叫有监督学习,先拿正确或者错误的案例给分类算法学习,然后输入问题、让算法给出正确分类。C4.5决策树,剪枝,信息熵
- 关联规则:如蝴蝶效应、啤酒和尿布放一起卖。支持度(support)商品组合发生概率,置信度(confidence)在A发生的情况下B发生的概率,提升度(lift)商品A的出现对商品B出现概率的提升程度
- 蒙特卡洛:使用随机数生成来模拟实验,并根据实验数据进行概率统计和推断,通过增加实验次数可以提高结果精确度,如计算圆周率。蒙特卡洛是一种概率随机性算法,得名于摩纳哥的蒙特卡洛赌场
- 拉斯维加斯:与蒙特卡洛算法不同,拉斯维加斯算法不断重复实验,在每次实验中应用确定性算法,再通过随机化来选择最佳实验方式,如八皇后问题
- 马尔可夫链:状态空间中经过从一个状态到另一个状态的转换的随机过程
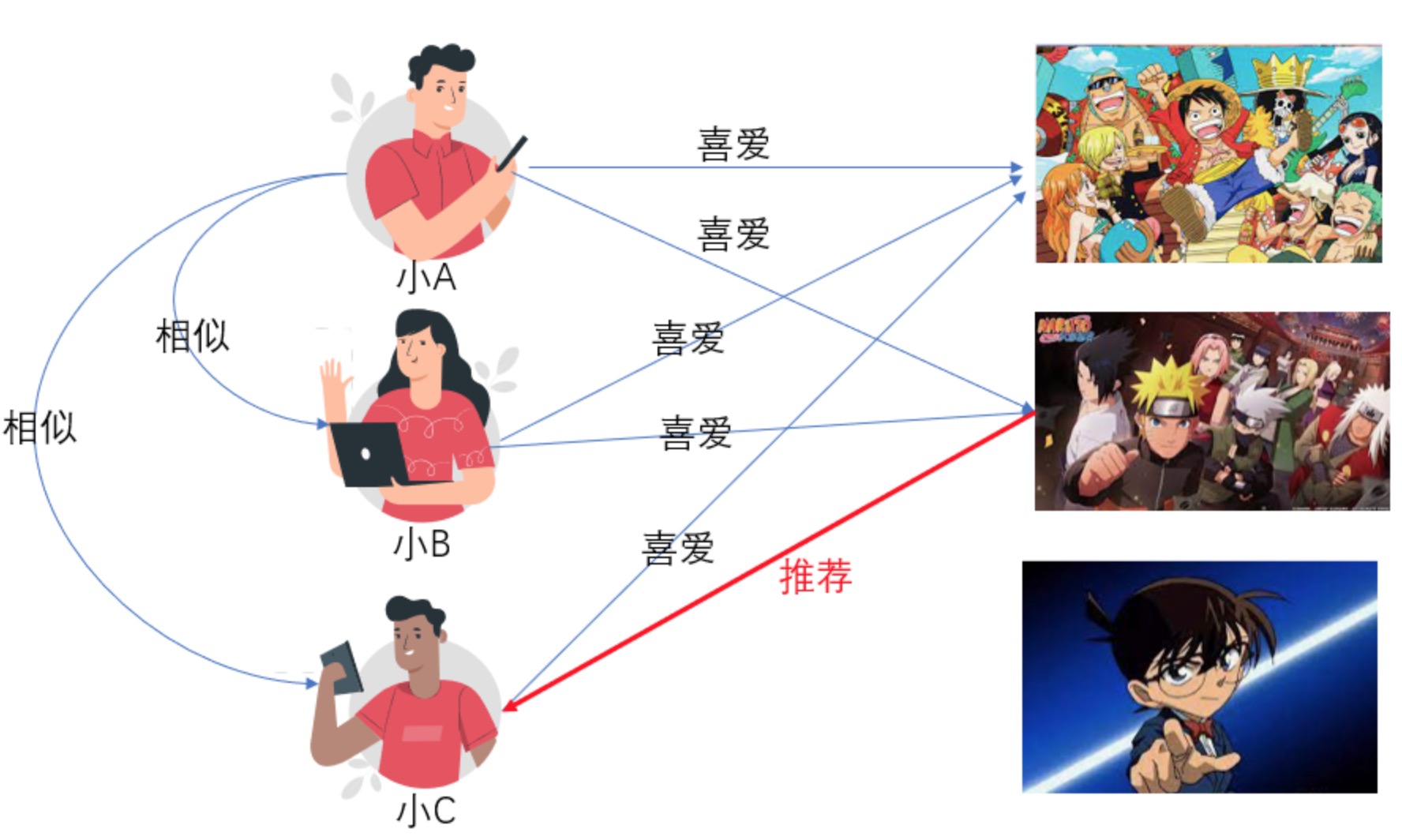
- 协同过滤:如商品推荐、头条推荐、音乐推荐等,常见算法有基于用户的协同过滤算法、基于物品的协同过滤算法、基于数据模型的协同过滤算法等,优点是相关性好、缺点是信息茧房(溺爱的妈妈)
分析步骤
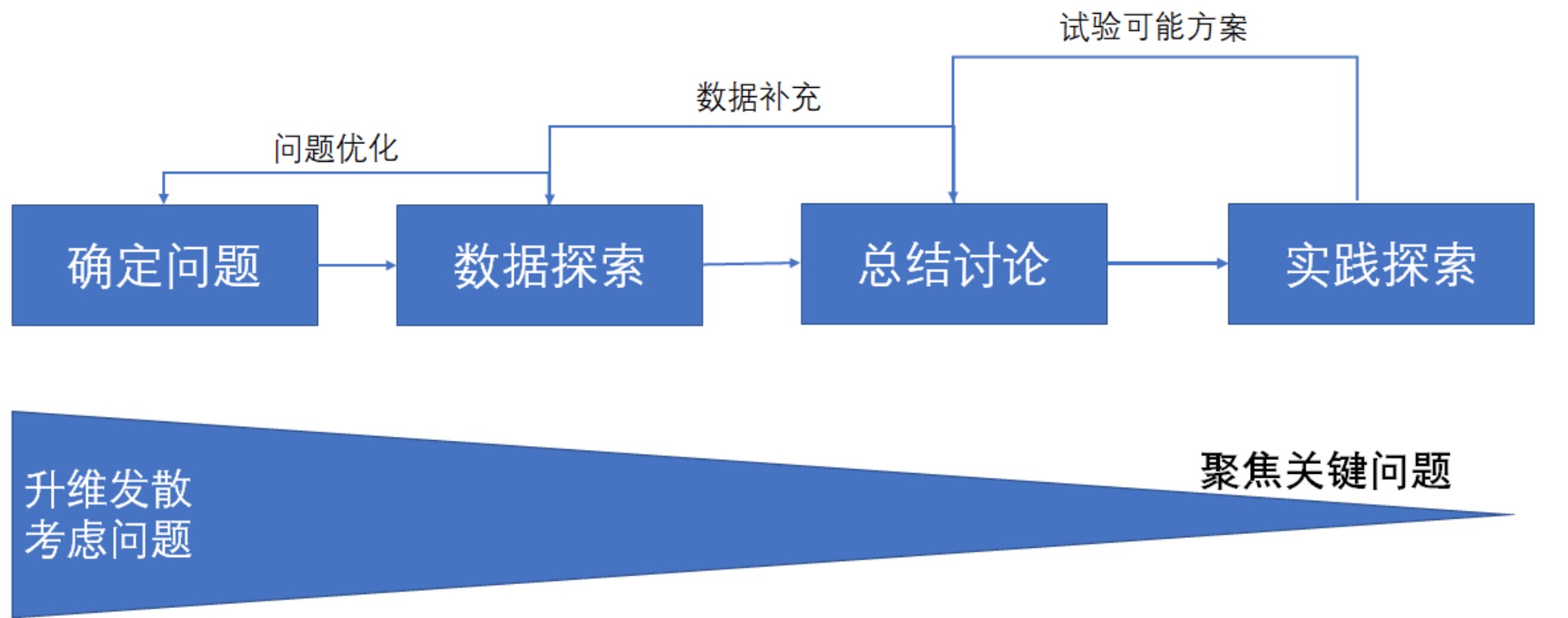
- 明确范围:和利益无关的问题,都不值得做数据分析。公司范围内,常用四象限分析法

- 确定问题:数据分析的重点在问题、不在数据,不要一上来就用手头数据进行分析,要先针对问题利用AsIs-ToBe和6W2H方法进行细化
- 采集数据:一手数据,来自企业内部数仓,尽量使用明细(主要);二手数据,来行业内的数据,如行业趋势、企业年报(参考);衍生数据,常用的三种拓展法即趋势分析法、快照扩展法、衍生指标法(延展)
- 写好故事:数据分析的结果以分析报告呈现,前面是大量的调研、梳理和思考(99%的定量分析),然后找到一个好故事线、来说明观点(1%的创见思维)
- 实践探索:用创新扩散模型,圈到第一批天使用户;用数据精益的方法,拆分实验、快速迭代、拿到结果;再用理性行为理论,说服干系人、让他们认可并落实你的想法
分析工具
- 直方图:展示数据的分布。柱子之间是连接的
- 柱状图:比较数据的大小。柱子之间有间隔
- Excel:小数据分析,Excel是最好的工具、没有之一
- BI工具:中数据分析,使用BI工具,包括存储、处理、展示
- 数据平台:大数据分析,典型如CDH,除存储、处理、展示外,还包括了数仓、挖掘、即系查询、治理等